
Akash Network stands at the forefront of Akash inference deployments for custom LLM models in 2026, with AKT trading at $0.3648 amid a modest 24-hour dip of -0.0289%. This decentralized Supercloud has transformed from a niche compute marketplace into a powerhouse handling millions of deployments, offering developers a scalable alternative to centralized giants. Providers earn AKT by supplying GPU resources across 80 and global data centers, driving down costs by up to 85% while ensuring low-latency performance for decentralized LLM models.
AkashML Emerges as the Go-To for Managed LLM Inference
AkashML represents a pivotal leap in Akash AI compute 2026, delivering fully managed AI inference on decentralized GPUs. Developers can spin up models like Llama 3.3-70B, DeepSeek V3, or Qwen3-30B instantly, tapping into predictable pay-per-token pricing. Take Llama 3.3 70B: $0.13 per million input tokens and $0.40 per million output tokens, a fraction of hyperscaler rates. New users snag $100 in credits, and OpenAI-compatible APIs mean seamless integration without rewriting code.
What sets AkashML apart is its open model lifecycle. Unlike black-box centralized services, users track updates, versions, and deprecations, upgrading at their pace. This transparency aligns with my long-term value investing philosophy: sustainable ecosystems thrive on trust and control, not vendor lock-in. Global scale across 65 and data centers ensures consistent latency, critical for real-time applications from chatbots to analytics pipelines.
AkashML offers decentralized AI inference with up to 85% cost savings, supporting real-time latency and automatic scaling.
Explosive Growth Fuels 2026 Momentum
Akash's trajectory underscores robust fundamentals. In 2025, deployments skyrocketed 466% from 553K to 3.1M, propelled by the AI infrastructure crunch. Q3 saw new leases rebound 42% quarter-over-quarter to 27,000, signaling renewed demand. Nous Research trained Nous Hermes 2 on Akash, proving production-grade viability for advanced models built on massive datasets.
Looking to 2026, the roadmap dazzles: NVIDIA B200/300 GPUs arrive for early access, alongside a December migration to a shared security chain. This bolsters scalability and security, positioning Akash as DePIN's linchpin alongside Render Network. AKT at $0.3648 reflects undervaluation; with AKT's utility in bidding for compute, rising inference demand should accrete value steadily.
Akash Network (AKT) Price Prediction 2027-2032
Forecasts based on AkashML LLM inference deployments, DePIN adoption, and decentralized AI compute growth from 2026 baseline ($0.36)
| Year | Minimum Price | Average Price | Maximum Price |
|---|---|---|---|
| 2027 | $0.45 | $1.05 | $2.50 |
| 2028 | $0.75 | $1.80 | $4.50 |
| 2029 | $1.10 | $2.90 | $7.50 |
| 2030 | $1.60 | $4.40 | $11.00 |
| 2031 | $2.20 | $6.50 | $16.00 |
| 2032 | $3.00 | $9.50 | $22.00 |
Price Prediction Summary
AKT is positioned for robust growth fueled by Akash Network's advancements in decentralized AI inference via AkashML, vLLM deployments, and global GPU scaling. From a 2026 baseline of $0.36, predictions reflect bullish adoption trends with average prices potentially rising 25x to $9.50 by 2032, while minimums account for market corrections and maximums capture super-bull scenarios amid AI/DePIN hype. Year-over-year average growth averages ~70%, tempered by cycles.
Key Factors Affecting Akash Network Price
- Explosive LLM deployment growth (466% YoY recently) and AkashML's 85% cost savings driving developer adoption
- Global infrastructure expansion to 80+ datacenters with NVIDIA B200/300 GPUs for low-latency inference
- DePIN sector tailwinds democratizing AI compute against centralized providers like AWS
- Crypto market cycles, including post-2028 Bitcoin halving bull runs boosting altcoins
- Community initiatives like HuggingFace integration and AkashChat enhancing ecosystem accessibility
- Regulatory clarity on DePIN/AI and competition from Render/Bittensor influencing market share
- Macro factors: AI infrastructure demand surge and AKT supply dynamics supporting higher market caps
Disclaimer: Cryptocurrency price predictions are speculative and based on current market analysis. Actual prices may vary significantly due to market volatility, regulatory changes, and other factors. Always do your own research before making investment decisions.
Community momentum amplifies this. A proposal to streamline HuggingFace LLM deployments targets 95% of text-to-text and text-to-image models, promising one-click setups. Initiatives like AkashChat enable multi-model inference without logins, fostering experimentation and privacy-focused apps.
Mastering vLLM Deployments on Decentralized Infrastructure
Deploying custom LLMs starts with vLLM, the efficient open-source inference engine. On Akash, it's straightforward: fund your wallet with AKT at $0.3648, grab the official container image, craft an SDL config, and launch. Within seconds, your API endpoint is live, scalable across providers' GPUs.
This process democratizes high-performance inference. Developers bid AKT for resources, matching supply with demand dynamically. No more overprovisioning idle servers; pay only for compute used. For custom models, containerize via Docker, tweak parameters for quantization or batching, and deploy globally. Akash's edge? Fault-tolerant leasing ensures uptime, with automatic failover across data centers.
From my vantage as a CFA charterholder tracking decentralized AI, Akash's model rewards patient capital. Centralized clouds grapple with capacity shortages; Akash tokenizes idle GPUs worldwide, unlocking trillions in latent compute. Early movers in inference deployments capture outsized yields as adoption surges.
Hands-on deployment reveals Akash's elegance. Providers compete on price and specs, so savvy developers optimize bids for cost-latency sweet spots. Quantize models to 4-bit for efficiency, or go full precision on NVIDIA B200s incoming via the 2026 roadmap. This flexibility suits everything from edge prototypes to enterprise-scale decentralized LLM models.
Step-by-Step: Launching Your Custom LLM on Akash
Master vLLM Deployment on Akash: Unlock Decentralized LLM Inference




Once deployed, monitor via Akash Console: track lease status, GPU utilization, and token spend. Scale horizontally by replicating services across providers; the marketplace handles load balancing. For production, integrate observability tools like Prometheus, all containerized seamlessly.
AkashChat exemplifies community ingenuity. This no-login platform lets users switch models mid-conversation, test prompts rapidly, and toggle privacy mode. Deploy it locally or on Akash for custom forks, ideal for researchers benchmarking Akash inference deployments across Llama, Mistral, or Qwen variants.
Pricing Transparency: AkashML vs. Traditional Clouds for Llama 3.3 70B Inference
| Provider | Input Cost per M Tokens | Output Cost per M Tokens | Est. Savings vs. AkashML |
|---|---|---|---|
| AkashML | $0.13 | $0.40 | ✅ Leader: Predictable Pay-per-Token, AKT Utility |
| AWS SageMaker | $0.85 | $2.60 | 85% 🟢 |
| GCP Vertex AI | $0.87 | $2.70 | 85% 🟢 |
| Azure ML | $0.89 | $2.67 | 85% 🟢 |
At $0.3648, AKT trades at a discount to its network value. Deployments hit 3.1M in 2025, up 466%; leases climbed 42% in Q3. As DePIN matures, Akash captures share from centralized chokepoints, especially with HuggingFace integration streamlining 95% of open LLMs.
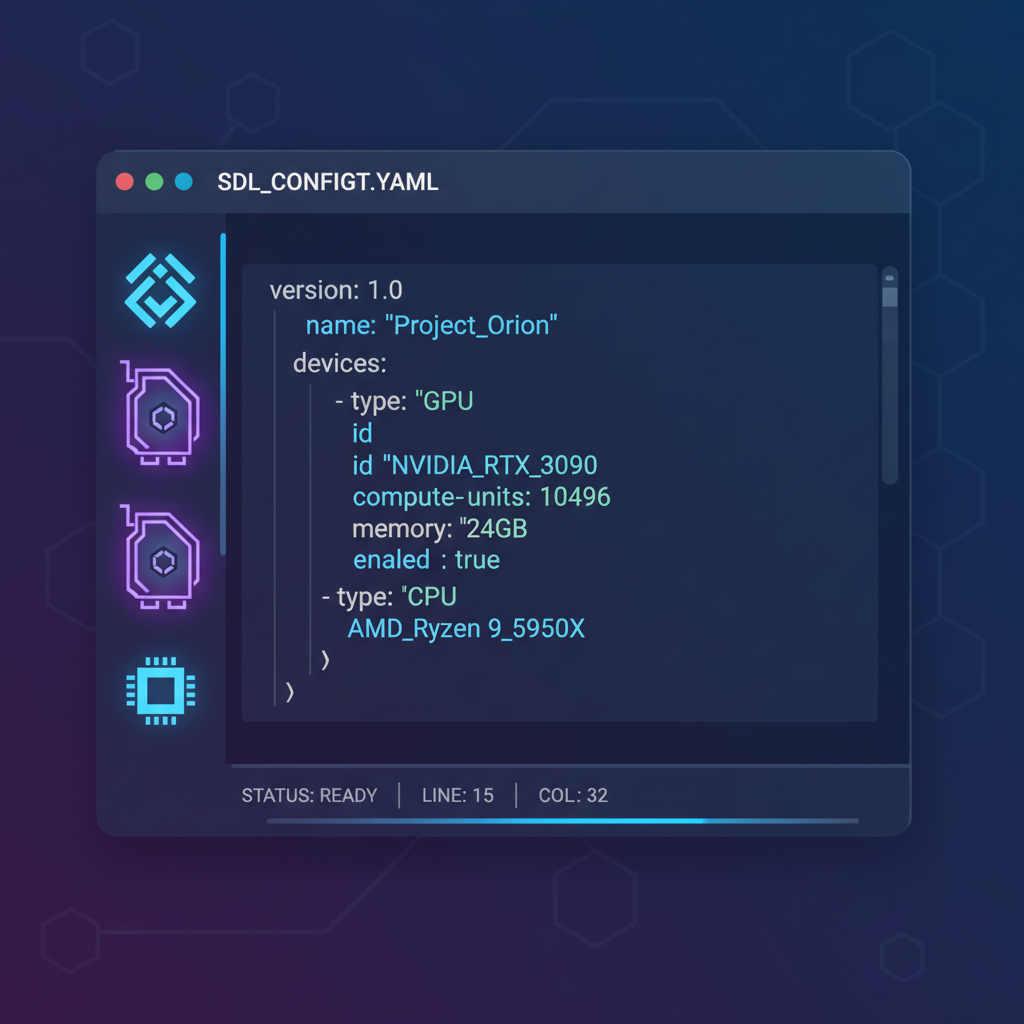
Code in Action: Sample vLLM SDL Deployment
Here's a distilled SDL blueprint for vLLM. Tweak GPU count, model path, and quantization for your needs. This YAML deploys a Llama endpoint ready for traffic.
vLLM Deployment SDL on Akash Network
Akash Network utilizes a YAML-based Service Definition Language (SDL) to declaratively specify deployments. The snippet below deploys vLLM, a high-performance inference engine for LLMs with native OpenAI API compatibility. Key elements include precise GPU resource requests for accelerator-equipped instances, port mappings for API access, environment variables to configure the model path, tokenization limits, and batching parameters, as well as scaling rules that enable automatic replica adjustment based on CPU and memory utilization thresholds for efficient resource management.
```yaml
---
services:
vllm:
image: vllm/vllm-openai:latest
command:
[
"bash",
"-c",
"python -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 8000 --model ${MODEL_ID} --served-model-name ${SERVED_MODEL_NAME} --gpu-memory-utilization 0.95 --max-model-len ${MAX_MODEL_LEN} --max-num-batched-tokens ${MAX_NUM_BATCHED_TOKENS} --max-num-seqs ${MAX_NUM_SEQS}"
]
envs:
- variable: MODEL_ID
value: "meta-llama/Llama-2-7b-chat-hf"
- variable: SERVED_MODEL_NAME
value: "llama2"
- variable: MAX_MODEL_LEN
value: "4096"
- variable: MAX_NUM_SEQS
value: "256"
- variable: MAX_NUM_BATCHED_TOKENS
value: "8192"
- variable: HF_TOKEN
value: "hf_xxxxxxxxxx"
expose:
- port: 8000
as: 80
to:
- global: true
proto: tcp - http
resources:
cpu:
units:
- count: 4
memory:
size: 16Gi
gpu:
units:
- count: 1
attributes:
akash.network/capabilities.gpu.vendor.nvidia.model.name: "RTX 4090"
scaling:
capacity:
count: 1
countMax: 5
target:
cpu: 70
memory: 80
```This SDL can be deployed via the Akash CLI with `akash tx deployment create vllm.sdl.yaml`. Educationally, note how GPU attributes ensure compatibility with high-end NVIDIA cards like RTX 4090, while scaling parameters prevent over-provisioning by targeting 70% CPU utilization. Customize env vars for your specific model and monitor via Akash Console for optimal inference performance.
Deploying this incurs AKT bids starting fractions of a cent per GPU-second, scaling with demand. Fault tolerance kicks in: if a provider drops, Akash migrates seamlessly. Pair with autoscaling policies, and you've got a resilient Akash AI compute 2026 stack.
Zoom out, and Akash embodies tokenized compute's promise. Idle data center GPUs worldwide become liquid assets, traded via AKT at $0.3648. Developers bypass Nvidia queues; investors stake on growth. The shared security chain migration by December 2026 fortifies this, slashing risks while inviting Cosmos ecosystem synergies.
For long-term holders, metrics scream opportunity. Revenue from leases funds development; TVL in provider collateral grows with adoption. Nous Hermes 2's training success previews inference dominance. As custom LLMs proliferate, Akash's edge in cost, scale, and openness positions it as infrastructure bedrock. Patient capital here aligns economics with innovation, yielding compounding returns in decentralized AI's ascent.




No comments yet. Be the first to share your thoughts!