Choose a verifiable inference protocol
Selecting the right verification layer depends on your tolerance for latency versus cost. Decentralized inference requires a mechanism to ensure that off-chain AI computations match the on-chain results. Without this, the system relies on blind trust, defeating the purpose of decentralization.
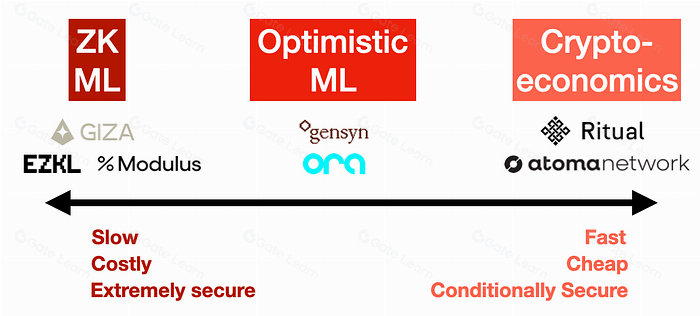
Three main approaches have emerged to tackle verifiable inference: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics. Each offers a different trade-off between security guarantees and computational overhead.
Comparison of Verification Models
| Feature | Zero-Knowledge (ZK) | Optimistic | Cryptoeconomic |
|---|---|---|---|
| Verification Cost | High (expensive proving) | Low (cheap verification) | Medium (staking rewards) |
| Latency | Immediate | Delayed (challenge period) | Immediate |
| Security Model | Mathematical proof | Fraud detection | Slashing penalties |
Zero-Knowledge Proofs
ZK proofs provide the strongest security guarantee. They generate a cryptographic proof that the AI model ran correctly without revealing the underlying data or model weights. This is ideal for high-stakes applications where correctness is non-negotiable. However, generating these proofs is computationally expensive and can introduce significant latency, making it less suitable for real-time applications.
Optimistic Verification
Optimistic approaches assume computations are valid unless proven otherwise. A challenge period allows other nodes to submit fraud proofs if they detect incorrect results. This model is significantly cheaper and faster than ZK, but it introduces a time delay. You must wait out the challenge window to finalize the result, which may not be viable for low-latency use cases.
Cryptoeconomic Incentives
This model relies on economic stakes rather than complex cryptography. Nodes stake tokens to participate in verification. If a node submits an incorrect inference, it loses its stake (slashing). This approach offers immediate finality and lower costs than ZK, but it relies on the assumption that the cost of attacking the network exceeds the potential reward. It is a practical middle ground for many current decentralized AI projects.
Configure node hardware and network settings
Setting up a decentralized inference node requires balancing raw compute power with strict network reliability. Unlike traditional cloud servers, your node must handle model loading, inference requests, and consensus verification simultaneously. This guide walks through the essential hardware and network configurations to ensure your node can participate in the network without becoming a bottleneck.
The graphics processing unit (GPU) is the core of your inference pipeline. For most decentralized inference protocols, NVIDIA GPUs with at least 24GB of VRAM are the standard. Consumer-grade cards like the RTX 3090 or 4090 are often preferred over enterprise data center cards because they offer a better price-to-performance ratio for running large language models (LLMs). Ensure your GPU supports the CUDA toolkit version required by your chosen inference framework (e.g., vLLM, TGI, or Ollama).
Decentralized inference relies on low-latency communication between nodes to aggregate predictions and reach consensus. A wired Ethernet connection is mandatory; Wi-Fi introduces jitter that can cause timeouts and failed verification steps. Aim for a stable upload speed of at least 100 Mbps. If your network has high latency, consider using a Content Delivery Network (CDN) or edge caching to reduce the round-trip time for model weights and inference results.
Beyond the GPU, allocate sufficient RAM (at least 64GB) and fast NVMe storage for model caching. Install the latest proprietary NVIDIA drivers and ensure your Linux kernel is up to date to support GPU passthrough if you are running the node in a virtualized environment. Disable power-saving modes in your BIOS and OS to prevent the GPU from throttling during intensive inference tasks.
The hardware you choose directly impacts your node's ability to serve requests within the 100ms latency windows required by many distributed inference stacks. Starting with a consumer-grade GPU and a robust network connection is often the most cost-effective way to enter the network.
Integrate the model into the distributed stack
Splitting a large language model across multiple nodes requires precise orchestration. The goal is to distribute computational load while maintaining sub-100ms latency for public-facing applications. This process involves sharding model weights, managing memory across heterogeneous hardware, and establishing a consensus protocol for aggregation.
Begin by partitioning the model into logical shards. Each node receives a subset of the layers or attention heads. This approach, often called tensor parallelism, allows multiple consumer GPUs to process different parts of the same token simultaneously. Ensure that the partitioning strategy aligns with the network bandwidth between nodes to avoid bottlenecks during weight transfer.
Install the inference runtime on each node. The runtime must handle incoming requests, route them to the correct shard, and manage local memory allocation. Projects like Wavefy demonstrate how to create a network where nodes act as both providers and consumers, dynamically adjusting to available compute resources. Verify that each agent can communicate with the central orchestrator via a reliable peer-to-peer protocol.
Once shards process their data, the results must be aggregated. Use a consensus mechanism to verify that the partial outputs from different nodes align. This step is critical for verifiable inference, ensuring that the final prediction is accurate and has not been tampered with. The aggregation layer combines the shard outputs into a coherent response, maintaining the integrity of the decentralized stack.

Continuously monitor the performance of the distributed stack. If latency exceeds thresholds, redistribute the shards or shift workloads to less congested nodes. Prime Intellect’s stack emphasizes engineering for 100ms latencies, which requires real-time adjustments to the network topology. Implement automated scaling rules to handle spikes in demand without degrading service quality.
Verify output integrity and handle failures
In a decentralized inference pipeline, you never assume a node’s result is correct. You verify it. Without cryptographic proof or a consensus mechanism, a single malicious or buggy node can poison your model’s output. This section walks through the sequence to validate results and manage failures.
Most decentralized inference networks require the node to submit a proof alongside the result. This is typically a zero-knowledge proof (ZKP) or an optimistic fraud proof. The ZKP mathematically certifies that the computation was executed correctly on the provided input without revealing the input itself. If your protocol uses an optimistic model, the node may submit the result immediately, but it must be prepared to defend it if challenged. Always configure your client to reject results that lack the required proof structure.
Before using the output, run the verification algorithm on your end. This step is computationally cheaper than re-running the full inference but strictly enforces correctness. If the proof fails verification, discard the result immediately. Do not cache or log the failed result as valid. In optimistic systems, you may need to wait for a challenge period to pass before the result is considered final, or actively participate in the challenge if you suspect fraud.
Single-node results are risky. Implement a fallback mechanism that requests the same inference from multiple nodes. Compare the outputs. If one node’s result differs significantly from the consensus of the others, flag it for review. This redundancy ensures that even if verification fails or is bypassed, you have a reliable aggregate result. Use a simple majority vote or a weighted average based on node reputation scores.
When a node fails verification or provides an invalid result, you must enforce penalties. This typically involves slashing a portion of the node’s staked tokens or blacklisting the node from future requests. Document the failure reason clearly for audit trails. If the failure rate exceeds a certain threshold across your network, pause requests and investigate the protocol health before resuming operations.
The core principle is "don't trust, verify." As noted in research on decentralized inference, the three main approaches—zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics—each offer different trade-offs between speed and security. Choose the verification method that aligns with your latency requirements and threat model. Always prioritize correctness over speed in high-stakes inference tasks.
Frequently asked questions about decentralized inference
Understanding decentralized inference requires separating general AI concepts from their specific application in blockchain ecosystems. Below are the most common questions regarding how these systems operate and how they differ from traditional models.
No comments yet. Be the first to share your thoughts!