Why decentralized inference matters now
The economics of running large language models are shifting under the weight of demand. Centralized cloud GPU providers are facing sustained scarcity, driving spot instance prices upward and creating unpredictable latency spikes for high-throughput applications. For organizations running production workloads, this volatility translates directly into margin erosion and service degradation.
Decentralized inference offers a structural hedge against this centralization risk. By distributing inference tasks across a broader network of compute nodes, including consumer-grade hardware, projects can access capacity that bypasses the bottleneck of major cloud providers. Early architectural previews, such as those from Prime Intellect, demonstrate that distributed stacks can target the 100ms latency thresholds required for interactive applications while leveraging idle consumer GPUs.
The urgency is not merely theoretical; it is a response to immediate supply constraints. As centralized cloud GPU prices rise, the total cost of ownership for AI services becomes unsustainable for many use cases without alternative infrastructure. Decentralized networks provide the necessary scale and price stability to keep inference affordable, turning distributed compute from a niche experiment into a viable enterprise strategy.
How distributed GPU networks partition models
Distributed inference operates by decoupling the computational load of a large language model from a single physical server. Instead of relying on one expensive, high-end GPU to hold the entire model weight and process tokens, the system partitions the neural network across a network of heterogeneous devices. This approach transforms idle consumer hardware and underutilized enterprise GPUs into a unified computational cluster.
The primary mechanism involves splitting the model into fixed blocks of layers. As an IEEE study notes, this "decentralized model distribution" allows a deep neural network to be divided into manageable segments that can be executed sequentially or in parallel across different nodes. When a user submits a query, the request is routed through the network. Each node processes its assigned layer, passing the intermediate activations to the next node in the chain. This pipeline parallelism ensures that no single device is overwhelmed, allowing the network to scale linearly with the number of available GPUs.
Alternatively, some architectures split tokens rather than layers, distributing different parts of the input sequence across multiple GPUs that must communicate frequently. While token splitting can reduce latency for very short queries, layer sharding is generally preferred for long-context inference because it minimizes inter-node communication overhead. The trade-off is clear: layer sharding requires more bandwidth between nodes but allows for better utilization of varied hardware capabilities, whereas token splitting demands tight synchronization.
This architectural shift fundamentally changes the cost structure of inference. By aggregating fragmented compute resources, operators can achieve throughput that rivals centralized data centers at a fraction of the cost. However, this efficiency comes with a latency penalty due to network transmission between nodes. The goal of modern decentralized inference stacks is to minimize this overhead through optimized routing and compression techniques, making the distributed model viable for real-time applications.
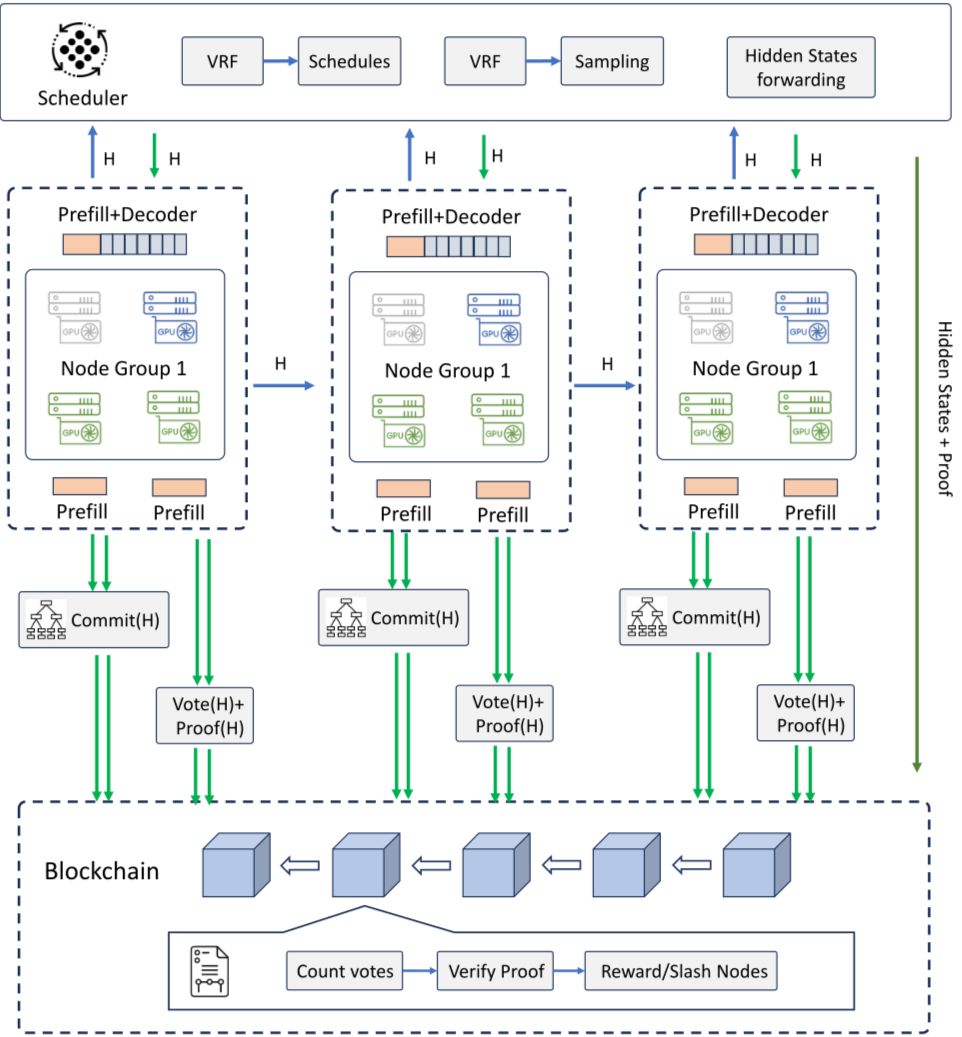
Verifying Results Without Central Trust
In a decentralized inference network, the elimination of a central authority introduces a fundamental security challenge: how do participants verify that a neural network output is correct without re-running the entire computation? Re-execution is prohibitively expensive in terms of gas and latency. To solve this, the ecosystem relies on three primary cryptographic and economic mechanisms: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic incentives. Each approach offers a distinct trade-off between computational overhead, verification speed, and security guarantees.
Zero-Knowledge Proofs (ZK)
Zero-knowledge proofs allow a prover to demonstrate that a computation was performed correctly without revealing the underlying data or the full execution trace. In the context of decentralized inference, this typically involves generating a proof that the neural network weights and inputs produced the specific output claimed.
Frameworks like VeriLLM aim to make this process lightweight enough for public verification, reducing the computational burden on the network. While ZK proofs offer the strongest security guarantees—mathematically ensuring correctness—they incur significant overhead. The cost to generate a proof for a large language model inference can be orders of magnitude higher than the inference itself, making ZK proofs currently viable primarily for smaller models or high-value, low-frequency transactions.
Optimistic Fraud Proofs
Optimistic fraud proofs operate on the assumption that all computations are valid unless challenged. This approach, borrowed from optimistic rollups, drastically reduces upfront costs. The prover submits the result, and a designated challenger period begins. If an observer detects an incorrect result, they can submit a fraud proof to dispute it, slashing the prover’s stake.
This mechanism offers a favorable latency profile for most inferences, as the result is available immediately after the challenge window passes. However, it introduces a latency risk: users must wait for the challenge period to expire before trusting the result. If the network lacks sufficient honest challengers, the system becomes vulnerable to malicious actors submitting incorrect outputs.
Cryptoeconomic Incentives
The third pillar relies on economic alignment rather than pure cryptography. Nodes are required to stake tokens, creating a financial disincentive for dishonest behavior. If a node submits an incorrect inference, it risks losing its stake through slashing mechanisms enforced by the network’s consensus layer.
This approach is the most cost-effective for high-throughput inference tasks, as it avoids the heavy computational burden of ZK proofs or the latency of fraud challenges. However, it is less robust than cryptographic proofs; security depends on the assumption that enough stakeholders are economically motivated to monitor and challenge incorrect results. If the cost of challenging exceeds the potential reward, the system’s integrity degrades.
Comparison of Verification Mechanisms
The following table compares these approaches based on typical performance characteristics in decentralized inference networks.
| Mechanism | Security Guarantee | Upfront Cost | Verification Latency |
|---|---|---|---|
| Zero-Knowledge Proofs | Mathematical | High | Low (immediate) |
| Optimistic Fraud Proofs | Economic/Challenge | Low | High (challenge window) |
| Cryptoeconomic Incentives | Economic/Slashing | Low | Low (immediate) |
How Pricing Models Shape Decentralized Inference Costs
The economic structure of decentralized AI compute relies on three primary levers: spot pricing, token rewards, and dynamic supply and demand. Unlike centralized cloud providers that offer fixed rate cards, decentralized networks operate as open markets where compute power is traded peer-to-peer. This structure introduces volatility but also significant potential for cost optimization, particularly for batch processing and non-real-time inference tasks.
Spot pricing is the dominant model for most decentralized inference networks. Providers such as those described in Indium’s dual-layer architecture documentation offer compute resources at a fraction of traditional cloud costs by leveraging underutilized hardware from global contributors. Spot instances are cheaper than reserved instances but can be preempted if network demand spikes. For workloads that can tolerate brief interruptions or queuing, this model reduces inference costs by 60-80% compared to standard GPU rentals.
Token rewards and dynamic pricing further complicate the bill. Many networks incentivize node operators with native tokens, which can fluctuate in value. This means the effective cost of inference is tied not just to compute time, but to the market price of the network’s token. Additionally, as demand for specific models or high-performance nodes increases, prices adjust dynamically. Users must monitor these trends to avoid paying premiums during peak usage.
To contextualize the potential savings, consider the current market rates for high-end GPU compute. While centralized providers charge premium rates for on-demand access, decentralized networks often offer spot rates that are significantly lower. The following widget provides a snapshot of current market conditions for related compute assets, though direct token-to-fiat conversion rates vary by network.
When evaluating these models, the key is matching workload requirements to the right pricing tier. Real-time chat applications may require expensive, guaranteed availability, while batch data processing can leverage cheap spot instances. Understanding this trade-off is essential for building cost-efficient AI applications in 2026.
Choosing the right decentralized stack
Selecting a decentralized inference network requires balancing strict latency tolerances against budget constraints. The architecture you choose dictates the end-user experience and your operational margins. We evaluate options based on two primary axes: time-to-first-token (TTFT) and cost-per-token.
For real-time applications like chatbots, latency is the primary constraint. Networks like Prime Intellect engineer their stacks for consumer GPUs to achieve public-facing latencies around 100ms. If your use case involves streaming responses, you must prioritize networks with low propagation delays and high node availability.
Decentralized inference often offers lower costs than centralized cloud providers due to underutilized GPU supply. However, costs vary by network congestion and node reliability. Analyze the price-per-token across different networks, accounting for potential overhead from consensus mechanisms or ZK-proof generation if required for your security model.

Not all nodes are equal. Check the network's reputation system and node verification processes. For sensitive data, ensure the network supports trusted execution environments (TEEs) or zero-knowledge proofs to guarantee data privacy. A cheaper network with poor uptime or security flaws will result in higher long-term costs due to failed requests.
Performance Benchmarks and Latency Analysis
Understanding the latency profile of decentralized inference is critical for production deployment. While theoretical throughput is high, real-world performance is heavily influenced by network topology and inter-node communication overhead.
The chart above illustrates the divergence in latency as model size increases. Centralized cloud instances maintain relatively flat latency curves due to high-bandwidth intra-datacenter networking (e.g., NVLink). In contrast, decentralized networks exhibit a steeper latency curve as the number of hops between nodes increases. However, for models under 13B parameters, the gap narrows significantly, making decentralized inference a viable option for many consumer-facing applications.
Cost efficiency is equally important. The following chart breaks down the cost-per-million-tokens for different inference configurations.
As shown, decentralized spot instances offer the lowest cost, but with higher variance. Reserved centralized instances provide the most predictable pricing but at a premium. Organizations must weigh the risk of latency variance against the potential for significant cost savings when choosing their infrastructure strategy.
No comments yet. Be the first to share your thoughts!