
What decentralized inference actually is
Decentralized inference fragments model execution across distributed nodes, reducing reliance on centralized cloud providers and lowering latency for real-time AI agents.
In a centralized architecture, AI inference is a monolithic process. A user sends a request to a single, powerful data center where a large language model (LLM) or neural network processes the input and returns the output. This model creates a bottleneck. As demand scales, the cost of maintaining massive GPU clusters in a few geographic locations skyrockets, and latency increases as data travels long distances.
Decentralized inference solves this by breaking the model down. Instead of one server handling the entire computation, the neural network is partitioned into blocks of layers. These blocks are distributed across a network of independent nodes. Each node processes its assigned segment of the model, passing the intermediate results to the next node in the chain. This approach mirrors how distributed computing has scaled the internet for decades, but applies it to the heavy computational load of AI.
The value proposition is immediate for AI agents and real-time applications. By processing data closer to the source or distributing the load, latency drops significantly. The economic model also shifts. Instead of paying a premium to a single cloud provider, users can access compute from a broader market of providers, often at a lower cost. This creates a more resilient infrastructure where the failure of one node does not bring down the entire service.
This shift is not just technical; it is structural. By treating compute as a commodity that can be sourced from anywhere, decentralized inference opens the door to a more open and competitive AI market. The technology is still maturing, but the trajectory is clear: as models grow larger, the limitations of centralized cloud inference will become more pronounced, driving adoption toward decentralized alternatives.
The latency bottleneck in centralized clouds
Centralized data centers are hitting a physical wall. As AI agents demand real-time responses, the distance between the user and the server creates an insurmountable friction. Latency requirements for real-time AI agents often fall below 100ms, a threshold difficult to meet with centralized cloud architectures due to network hops. Every millisecond added by routing through a single regional hub erodes the utility of autonomous systems.
Decentralized inference addresses this by distributing compute closer to the edge. Instead of funneling all requests through a few massive facilities, workloads are split across a mesh of nodes. This architecture mirrors how human neural networks process information—locally and in parallel—rather than sending every thought to a single processing center.
The economic implications are stark. Centralized providers charge a premium for low-latency access, creating a bottleneck that stifles innovation. By leveraging underutilized consumer GPUs and edge devices, distributed networks can offer inference at a fraction of the cost. This shift is not just technical; it is a market correction.
Projects like Prime Intellect are already engineering stacks designed for consumer hardware to hit these 100ms targets. The move away from monolithic data centers toward a distributed GPU network is the only viable path to scalable, low-latency AI.
How distributed GPU networks operate
Decentralized inference replaces the monolithic data center with a fragmented mesh of compute nodes. This architecture addresses the bottleneck of centralized training by distributing the inference workload across a global network. The primary advantage is economic and operational: it leverages underutilized consumer-grade hardware to serve enterprise AI demand without the capital expenditure of proprietary infrastructure.
Model Sharding and Parallel Processing
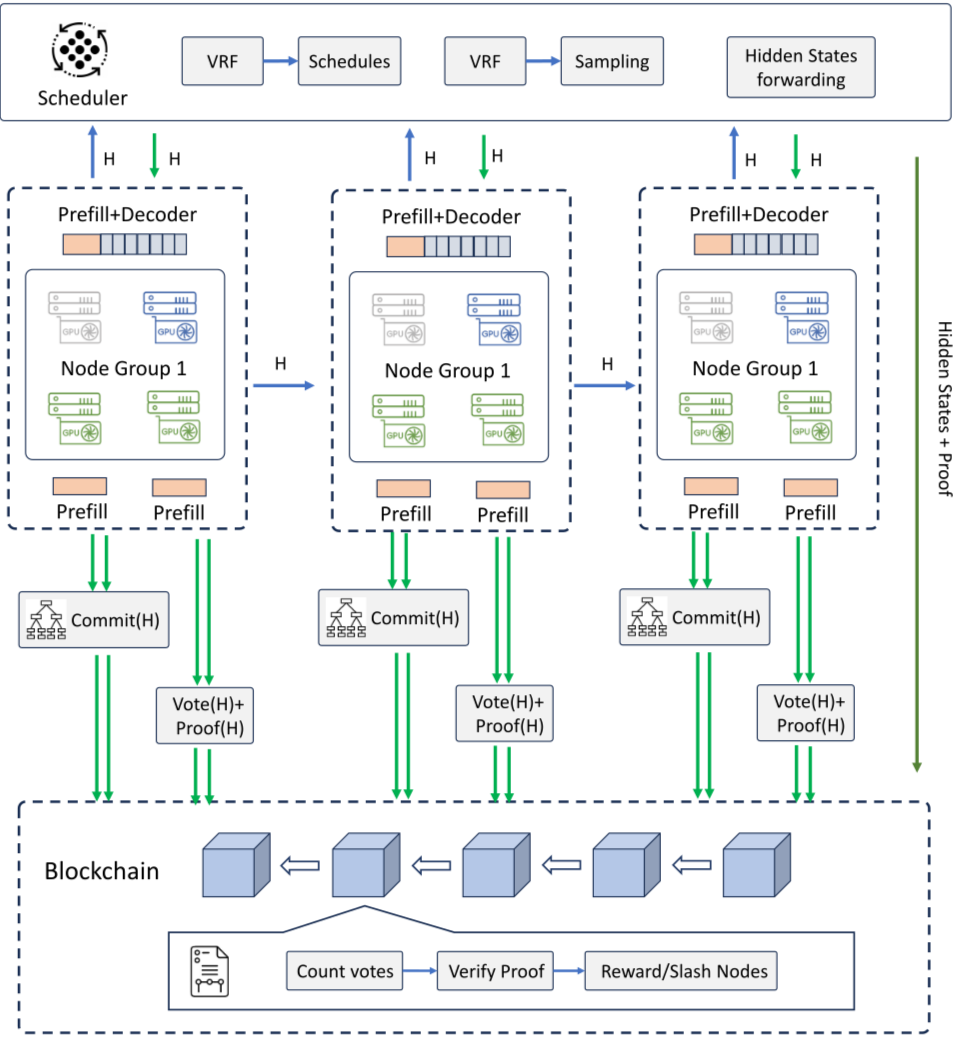
The core mechanism enabling this scale is model sharding. Large Language Models (LLMs) are too massive for single consumer GPUs. Projects like Wavefy split these models into tensor shards, distributing layers across multiple devices. Each node computes a portion of the neural network's forward pass, then passes intermediate activations to the next node in the chain.
This parallelization requires high-bandwidth communication between nodes. The latency penalty of transmitting tensors over the internet is offset by the massive parallelism achieved. The result is a cost-per-inference that is significantly lower than cloud providers, provided the network can maintain low latency and high reliability. The system treats compute as a fluid resource, routing requests to the nearest available nodes with sufficient capacity.
Dual-Layer Architecture for Verification
Security and accuracy in a trustless environment are managed through dual-layer architectures. As detailed in Indium’s research, this system separates the execution layer from the verification layer. The execution layer handles the actual inference on consumer hardware. The verification layer, often utilizing zero-knowledge proofs or cryptographic attestations, validates that the computation was performed correctly and without tampering.
This separation ensures that the decentralized network is not just a collection of unreliable devices, but a provably correct computational engine. It allows enterprises to deploy sensitive AI models on untrusted hardware while maintaining data privacy and result integrity. The verification cost is amortized across the entire network, making it viable for high-volume inference tasks.
The Role of Consumer-Grade Hardware
Consumer GPUs, such as NVIDIA’s RTX series, form the backbone of these networks. Their high performance-per-dollar ratio makes them ideal for inference, which is less compute-intensive than training. However, their heterogeneity presents a challenge. Managing drivers, memory limits, and network stability across thousands of diverse devices requires sophisticated orchestration.
Networks like Cortensor address this by abstracting the hardware complexity. They provide a unified interface for developers, hiding the underlying fragmentation of consumer GPUs. This abstraction layer ensures that the application layer interacts with a consistent API, regardless of the physical node executing the request. This scalability is critical for moving decentralized inference from experimental pilots to production-grade financial and medical applications.
The market interest in this infrastructure is reflected in the performance of related tokens. RENDER Network, a leading provider of decentralized GPU compute, shows strong correlation with broader AI infrastructure trends. Investors are pricing in the potential for decentralized inference to disrupt traditional cloud AI markets. The volatility in these assets highlights the speculative nature of the sector, but the underlying technical demand for compute remains robust.
Implementation Checklist
-
Evaluate Model Size: Determine if your LLM can be effectively sharded across consumer GPU memory limits.
-
Assess Latency Requirements: Measure the acceptable latency threshold for your application to ensure network transmission times do not degrade user experience.
-
Verify Security Protocols: Confirm that the chosen network utilizes cryptographic verification (e.g., ZK-proofs) to ensure inference integrity.
-
Test Orchestration Layer: Validate that the network’s abstraction layer can handle your specific hardware configurations and driver versions.
-
Monitor Node Reliability: Implement monitoring for node downtime and latency spikes to maintain service level agreements (SLAs).
Verifying results without trusting nodes
In decentralized inference, the central paradox is that you must trust the output without trusting the machine. When computing nodes operate across untrusted networks, the standard verification model—checking code execution step-by-step—collapses under the weight of latency and cost. To maintain data integrity in these environments, the industry has converged on three primary cryptographic and economic mechanisms: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic incentives.
Zero-Knowledge Proofs
Zero-knowledge proofs (ZKPs) provide the strongest guarantee of correctness by allowing a node to prove a computation was executed correctly without revealing the underlying data or the computation itself. In the context of decentralized AI, this means a prover can demonstrate that a neural network inference produced a specific result, ensuring no tampering occurred during processing. While computationally expensive, ZKPs are essential for high-stakes financial applications where absolute certainty is required, as they eliminate the need for any trust in the provider.
Optimistic Fraud Proofs
Optimistic fraud proofs operate on a different premise: they assume all computations are valid unless challenged. This approach drastically reduces upfront computational overhead, making it more scalable for real-time inference tasks. If a node detects an invalid result, it can submit a fraud proof to the network, which then triggers a dispute resolution process. This mechanism is widely adopted in layer-2 scaling solutions and offers a practical balance between speed and security, though it introduces a time delay for finality during disputes.
Cryptoeconomic Incentives
Cryptoeconomic incentives align the financial interests of node operators with network integrity. By staking capital that can be slashed for malicious behavior, nodes are economically disincentivized from producing incorrect results. While this method does not provide cryptographic proof of correctness, it creates a high barrier to entry for attackers. In decentralized inference markets, this economic layer often works in tandem with the other two methods, serving as a final line of defense against systemic fraud.
Market dynamics and investment signals
The decentralized inference market is shifting from experimental testnets to production-grade infrastructure. Capital is flowing toward networks that solve the latency and reliability gaps left by centralized cloud providers. Investors are no longer betting on abstract concepts; they are backing distributed stacks engineered for consumer GPUs and sub-100ms response times, a threshold critical for real-time AI agents [primeintellect.ai].
This transition creates a bifurcated market. On one side, established cloud giants continue to dominate high-margin enterprise workloads. On the other, decentralized networks like Cortensor are capturing niche markets by offering robust, scalable inference with enhanced security and lower costs [cortensor.network]. The financial implication is clear: infrastructure that fragments compute across participants will likely capture long-tail demand, while centralized players defend premium tiers.
Market sentiment is currently driven by the viability of these distributed architectures. We are tracking relevant decentralized compute assets to gauge real-time investor confidence and liquidity flows. A live price feed provides immediate insight into how the market values these emerging infrastructure protocols.
Common questions about decentralized inference
Decentralized inference represents a structural shift in how AI workloads are distributed, moving away from centralized data centers toward networked edge nodes. This model partitions deep neural networks into fixed blocks of layers, distributing the computational burden across independent participants while maintaining verifiable integrity through zero-knowledge proofs or optimistic fraud proofs [1].
What is decentralized computation?
Decentralized computing allocates hardware and software resources across individual workstations or distributed nodes rather than relying on a single central server. In the context of AI, this means training and inference tasks are fragmented and processed simultaneously by a network of contributors, reducing latency and increasing resilience against single points of failure.
Is AI centralized or decentralized?
Traditional AI remains centralized, consolidating data, compute power, and governance within proprietary clouds. Decentralized AI fragments these elements, using blockchain for identity, incentives, and secure ledgering of contributions. This shift allows for open participation, where models are not controlled by a single entity but are collectively maintained and improved by the network [2].
What is an inference in crypto?
In cryptographic and blockchain contexts, inference refers to the process of generating outputs from a trained model without revealing the underlying weights or data. This often involves "verifiable inference," where the network proves that a computation was performed correctly without re-executing the entire heavy workload, ensuring trustlessness in decentralized AI services [1].
No comments yet. Be the first to share your thoughts!