Understand decentralized inference basics
Decentralized inference distributes model execution across a network of independent nodes rather than relying on a single centralized cloud provider. In this setup, individual nodes process requests and aggregate results using a consensus protocol to ensure accuracy and security. This architecture shifts the computational burden away from monolithic data centers, offering a path to reduce costs and latency for AI applications.
Unlike traditional cloud inference, where all traffic flows through a few major providers, decentralized networks leverage idle compute resources from a global pool. This distribution can lower operational expenses by avoiding vendor lock-in and peak pricing. It also enhances resilience; if one node fails, the network continues to function, preventing single points of failure that often plague centralized systems.
The primary challenge lies in verification. Ensuring that a node actually performed the correct computation without cheating requires cryptographic methods like zero-knowledge proofs or optimistic fraud proofs. These mechanisms maintain trust in a permissionless environment, allowing users to verify results without re-running the entire inference process themselves.
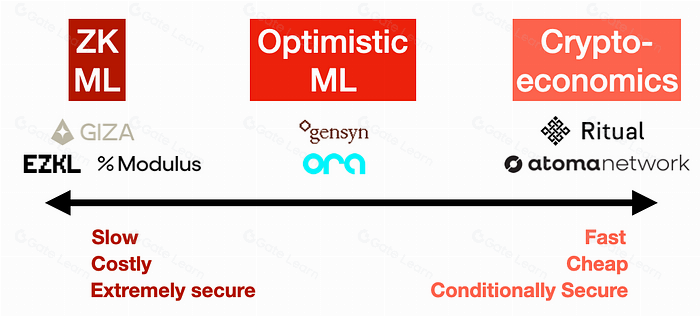
Choose the right verification method
Decentralized inference relies on a fundamental trust problem: how do you verify an AI model’s output when the code running it is opaque or proprietary? In a trustless environment, you cannot simply trust the node. Instead, you must choose a cryptographic or economic mechanism that guarantees correctness.
Three primary methods have emerged to tackle verifiable inference: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic incentives. Each offers a different trade-off between computational cost, latency, and security guarantees. Selecting the right method depends on your specific threat model and budget constraints.
Compare Verification Methods
The following comparison highlights the core differences between the three primary verification approaches. Use this to determine which model fits your deployment’s latency and cost requirements.
| Method | Computational Cost | Latency | Security Guarantee |
|---|---|---|---|
| Zero-Knowledge Proofs | Very High | High | Mathematical Guarantee |
| Optimistic Fraud Proofs | Low | Medium | Economic/Time-Limited |
| Cryptoeconomic Incentives | Low | Low | Probabilistic/Stake-Based |
Zero-Knowledge Proofs (ZKPs)
Zero-knowledge proofs provide the strongest security guarantee. They allow a node to prove that it executed the inference correctly without revealing the underlying model weights or input data. This is achieved by generating a cryptographic proof that the computation adheres to the specified constraints.
However, ZKPs are computationally expensive. Generating a proof for a large AI model can require significant time and resources, often making real-time inference impractical. They are best suited for high-stakes applications where correctness is non-negotiable and latency is secondary, such as financial auditing or regulatory compliance.
Optimistic Fraud Proofs
Optimistic fraud proofs assume that nodes are honest by default. The inference result is accepted immediately, but a challenge period follows during which anyone can submit a "fraud proof" if they detect an error. If a fraud proof is submitted and verified, the dishonest node is penalized (slashed).
This method drastically reduces computational overhead since proofs are only generated during disputes. However, it introduces latency due to the challenge period. Users must wait for the window to close before they can fully trust the result. This approach is ideal for applications where occasional delays are acceptable, but immediate verification is not required.
Cryptoeconomic Incentives
Cryptoeconomic verification relies on economic stakes rather than complex cryptography. Nodes stake tokens to participate in inference. If a node provides incorrect results, it loses its stake. While this does not mathematically prove correctness, the economic penalty for cheating discourages malicious behavior.
This is the most efficient method in terms of cost and latency, making it suitable for high-throughput applications. However, it offers only probabilistic security. If the cost of attacking the network is lower than the value of the stake, the system remains vulnerable. It is best for applications where the cost of being wrong is low or where multiple nodes can cross-verify results.
Integrate the inference SDK
Connecting your application to a decentralized inference network requires installing the provider’s SDK, configuring the client, and routing requests through the distributed nodes. Unlike centralized APIs, you are not calling a single server; you are interacting with a network of independent compute providers.
The workflow mirrors standard API integration but adds a layer of network discovery and node selection. You will initialize the SDK with your credentials, select a model available on the network, and submit requests that are routed to the best-performing nodes.

Begin by installing the official SDK for your chosen network. Most networks provide language-specific libraries (Python, TypeScript, Go) that handle the complex logic of node discovery and request routing.
For example, Prime Intellect offers a Python client that manages connections to their distributed inference stack 1. Wavefy provides a similar decentralized LLM inference system 2. Install the package via your standard package manager:
pip install primeintellect
# or
npm install @wavefy/sdk
This step establishes the local interface between your application and the decentralized network.
After installation, import the client and initialize it with your API key or wallet credentials. Decentralized networks often require wallet signatures for billing or access control, unlike traditional API keys.
from primeintellect import Client
client = Client(
api_key="your_api_key_here",
network="mainnet" # or testnet for development
)
Ensure you are pointing to the correct network environment. Testnet environments allow you to verify connectivity without incurring costs on mainnet token swaps.
Decentralized networks aggregate models from various providers. You must query the network’s registry to find available models and their current availability.
models = client.list_models()
# Filter for a specific model, e.g., Llama-3-8B
model = next(m for m in models if m.name == "llama-3-8b")
This step ensures you are routing requests to a model that is actively hosted and verified by the network nodes. Check latency and cost metrics if the SDK provides them.
Once the client is initialized and a model is selected, submit requests just as you would to a standard LLM API. The SDK handles the routing to the best available nodes.
response = client.chat.completions.create(
model=model.id,
messages=[{"role": "user", "content": "Explain quantum computing."}]
)
print(response.choices[0].message.content)
The network aggregates responses from multiple nodes if configured for consensus, or returns the fastest valid response. Monitor the response time to ensure it meets your application’s latency requirements.
Handle latency and network errors
Decentralized inference introduces inherent latency because requests must traverse a distributed network of nodes rather than a single, optimized data center. Unlike centralized clouds where compute resources are co-located, decentralized systems rely on consensus and node availability, which can result in unpredictable response times. To maintain a functional user experience, you must implement robust error handling and latency mitigation strategies directly in your application layer.
Implement Exponential Backoff and Retry Logic
Network nodes in decentralized inference networks may go offline or become temporarily unresponsive due to hardware constraints or network congestion. Blindly retrying failed requests can overwhelm the network and worsen latency. Instead, implement exponential backoff with jitter. This strategy increases the wait time between retries exponentially, while adding a random "jitter" component to prevent a thundering herd problem where all clients retry simultaneously.
Configure your client to retry failed requests up to a reasonable limit (e.g., 3 attempts). Ensure each retry targets a different node if possible, leveraging the decentralized nature of the network to find an available resource. This approach aligns with best practices for handling transient failures in distributed systems, as noted in discussions on decentralized inference challenges.
Use Local Caching for Stable Responses
Latency is often most damaging when the same request is repeated. If your application generates or processes data that does not change frequently, implement local caching. Cache the response from the decentralized network for a defined TTL (Time-To-Live). When a subsequent request arrives, serve it from the local cache instead of querying the network. This significantly reduces the perceived latency for end-users and decreases the load on the decentralized node network.
Configure Fallback Mechanisms
Decentralized networks are not immune to downtime. If all available nodes fail to respond within a specified timeout, your application should not hang indefinitely. Implement a fallback mechanism that either returns a cached stale response, serves a simplified local model, or returns a clear error message to the user. This ensures that your application remains resilient even when the decentralized inference layer is experiencing significant network errors or high latency.
Decentralized networks often exhibit higher latency than centralized clouds. Implement exponential backoff and local caching to mitigate user-facing delays.
Verify output integrity
Once the decentralized network returns an inference result, you must confirm it matches the ground truth before trusting the output. This verification step relies on the cryptographic proof method selected during deployment, such as zero-knowledge proofs or optimistic fraud proofs.
If your network uses zero-knowledge proofs, the verification process involves validating the proof against the public parameters. You can use official verification libraries provided by the inference protocol to check the proof's validity. A valid proof confirms that the computation was performed correctly without revealing the underlying data.
For networks relying on optimistic fraud proofs, the process is slightly different. You must monitor the output window for any challenge submissions. If no fraud proof is submitted within the specified timeframe, the result is considered verified. Always implement automated checks to detect invalid outputs early, ensuring data integrity across your application.
Check your deployment setup
Before routing live traffic to your decentralized inference network, run through this pre-launch checklist. The goal is to verify that your model is secure, cost-effective, and performant across the distributed nodes.
Security and Verification
Decentralized nodes may behave deceitfully, so you must ensure your verification layer is active. Whether you are using zero-knowledge proofs or optimistic fraud proofs, verify that the consensus mechanism correctly rejects invalid outputs. Without this, the integrity of your inference is compromised.
Latency and Performance
Decentralized inference often struggles with latency compared to centralized data centers. Test your model’s response time against the 100ms benchmarks required for consumer-grade applications. If latency is too high, consider adjusting your sharding strategy or selecting nodes with better network proximity.
Cost and Resource Allocation
Ensure your billing or tokenomics model accurately reflects the computational load. Splitting large LLM models across nodes should reduce costs, but inefficient routing can lead to unexpected expenses. Monitor resource usage during a beta test to confirm that your budget aligns with actual inference volume.
Common questions about decentralized inference
Decentralized inference shifts model execution from centralized clouds to distributed node networks. This FAQ addresses specific technical distinctions and verification methods to clarify how these systems operate.
Understanding these distinctions helps in selecting the right architecture for your deployment. Always verify the consensus mechanism used by the network to ensure it aligns with your security requirements.
No comments yet. Be the first to share your thoughts!