Spotting hallucinations in centralized models
When you call a centralized LLM API, you engage in a blind transaction. The provider returns text but offers no cryptographic proof that the output is correct, grounded, or consistent with the input. In production, this lack of verifiability turns every inference into a liability. You cannot distinguish between a subtle factual error and a confident fabrication without external tools.
This trust problem is structural. Model weights and inference logic are proprietary black boxes. When a hallucination occurs, you cannot audit the specific neuron activation or attention head that led to the error. You are left with a binary outcome: the output is either accepted as truth or rejected as noise. There is no intermediate layer of cryptographic assurance to validate the reasoning path.
In high-stakes applications, this opacity is unacceptable. A single unverified hallucination in legal, medical, or financial contexts can result in significant reputational damage or regulatory penalties. The cost of fixing these errors post-deployment far exceeds the overhead of implementing verification mechanisms. Decentralized inference addresses this by shifting from trust-based assumptions to verification-based guarantees.
How decentralized inference splits the workload
Decentralized inference treats a large language model as a collection of smaller, independent layers rather than a single monolith. Instead of requiring one powerful GPU to hold the entire model in memory, the system fragments the model into blocks and distributes them across a network of available edge devices. This architectural shift moves the bottleneck away from centralized data centers and into a distributed mesh of consumer-grade hardware.
The process follows a strict sequential flow to ensure data integrity and result accuracy:
The user submits a prompt. The orchestrator node analyzes the request and identifies the specific model layers required for inference. It then queries the network for available edge nodes that hold the necessary shards of the model and have sufficient compute capacity.
The model weights are split into discrete blocks. Each block is assigned to a specific node in the network. Communication protocols establish secure channels between these nodes, ensuring that intermediate activations (the data passed between layers) are transmitted correctly and without tampering.
Each edge node processes its assigned layer. Node A computes the first layer and sends the output to Node B, which computes the next layer, and so on. This pipelined execution allows multiple requests to be processed simultaneously across different parts of the network, significantly increasing throughput.
The final output from the last layer is aggregated and returned to the user. Cryptographic proofs verify that each node executed its layer correctly and that the intermediate data was not altered during transit. If any proof fails, the request is discarded or re-routed to a different set of nodes.
This fragmentation strategy directly addresses the cost and reliability issues of centralized inference. By leveraging idle consumer GPUs, the system reduces the cost per token significantly. More importantly, it eliminates single points of failure. If one node goes offline, the orchestrator can dynamically reassign its workload to other available nodes, ensuring the service remains operational without interruption.
The verification mechanism is critical here. Because the model is split across untrusted or semi-trusted nodes, the system uses cryptographic commitments to prove that each node performed the correct mathematical operations on the data it received. This ensures that the final output is not just a guess from a random node, but a mathematically verified result of the distributed computation.
Verifying outputs with zero-knowledge proofs
Decentralized inference shifts the trust model from relying on a single provider’s reputation to relying on cryptographic guarantees. The core problem with standard LLM outputs is that they are opaque; you see the text, but you cannot verify the computation that produced it. Zero-Knowledge Machine Learning (ZK-ML) solves this by generating a cryptographic proof that the model executed correctly on the specific input data provided.
How ZK-ML Proofs Work
In a traditional setup, an AI provider runs a model and returns a result. With ZK-ML, the provider (the prover) generates a proof alongside the output. This proof attests that the computation was performed according to the pre-defined model circuit and that the input data matches the claimed source. A verifier can then check this proof instantly without re-running the entire, often massive, inference process.
This mechanism creates a "don't trust, verify" environment. If a provider attempts to hallucinate or return incorrect results, the cryptographic proof will fail validation. This ensures that the output is not just a plausible-sounding guess, but a verified execution of the model’s logic on the given data.
The Verification Flow
The process involves three main steps: circuit compilation, proof generation, and verification.
- Circuit Compilation: The ML model is converted into an arithmetic circuit. This translates mathematical operations (like matrix multiplications in neural networks) into constraints that can be proven.
- Proof Generation: The provider runs the inference on the compiled circuit. Instead of just outputting the result, the system generates a succinct proof (such as a SNARK or STARK) that attests to the correct execution.
- Verification: The verifier checks the proof against the public parameters and the claimed input/output. This step is computationally cheap compared to re-running the model.
Practical Implementation with VeriLLM
Recent frameworks like VeriLLM demonstrate how to make this practical for large language models. They optimize the circuit compilation to reduce the overhead of proving LLM inference, which is typically too heavy for standard ZK systems. By focusing on the most critical parts of the computation, these frameworks allow for publicly verifiable inference that is efficient enough for real-world use.
sequenceDiagram
participant User
participant Provider
participant Verifier
User->>Provider: Send Input Data
Provider->>Provider: Run ML Model (Circuit)
Provider->>Provider: Generate ZK Proof
Provider->>User: Return Output + Proof
User->>Verifier: Submit Proof + Output
Verifier->>Verifier: Verify Proof
Verifier-->>User: Valid/Invalid
This flow ensures that the data integrity is maintained from input to output. Any deviation in the computation, whether due to error or malicious intent, is caught by the verification step. This is the foundational layer for trustworthy decentralized AI.
Choosing a decentralized inference provider
Selecting a network for decentralized inference requires shifting focus from raw throughput to verification integrity. The primary risk in this architecture is not latency, but the potential for a node to return a hallucinated response without immediate detection. Your evaluation must center on how the network proves computational correctness before the result reaches the user.
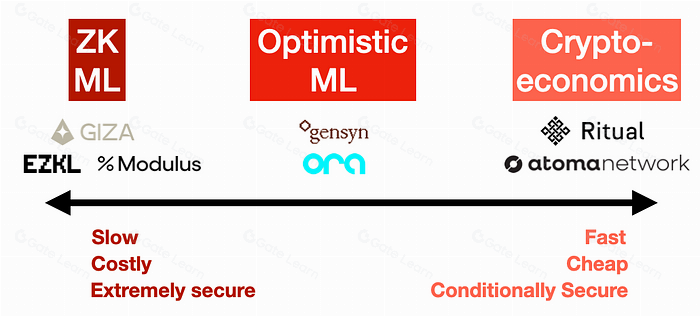
The first check is the proof system. Determine whether the network uses Zero-Knowledge (ZK) proofs or Optimistic verification. ZK systems generate a cryptographic proof that the computation was executed correctly, offering immediate finality but often at a higher computational cost. Optimistic systems assume correctness by default and only require proof during a dispute window, which lowers costs but introduces a delay in settlement. For applications where hallucination carries high liability, ZK proofs are the standard for trust minimization.
Node reliability and geographic distribution are the next critical metrics. A network with nodes clustered in a single data center or region is vulnerable to localized outages and censorship. Look for providers that distribute inference tasks across a diverse set of independent operators. This decentralization ensures that no single point of failure can disrupt the service or collude to inject biased outputs. The image below illustrates the interconnected nature of these distributed nodes, highlighting the importance of a resilient, wide-area network topology.
Finally, assess the cost structure relative to verification overhead. Decentralized inference is not always cheaper than centralized cloud APIs when you factor in the gas fees for submitting proofs or the staking requirements for node operators. Ensure the provider’s pricing model accounts for the verification layer so that the total cost of a verified, hallucination-free response remains competitive.
-
Is the proof system ZK (immediate finality) or Optimistic (dispute-based)?
-
What is the average time to generate a cryptographic proof for an inference?
-
Are nodes geographically distributed to prevent single points of failure?
-
Does the pricing model include the cost of verification gas and staking?
Common Pitfalls in Verifiable AI Deployment
Implementing decentralized inference shifts the trust model from provider reputation to cryptographic verification, but this transition introduces distinct operational friction. When you move from a centralized API to a distributed network of nodes generating zero-knowledge proofs or recursive verifications, you are no longer just managing software; you are managing computational overhead and economic incentives. The most immediate hurdles involve latency, node reliability, and the complexity of integrating these verification layers into existing Large Language Model (LLM) stacks.
High Latency from Proof Generation
The primary symptom of a struggling verifiable inference pipeline is sudden, unpredictable latency spikes. Generating cryptographic proofs—whether through zkVMs or recursive SNARKs—is computationally intensive. Unlike standard inference, where the bottleneck is usually GPU memory bandwidth, verifiable inference adds a post-processing step that can take minutes or even hours for complex models.
To mitigate this, you must separate the inference task from the verification task. Do not attempt to generate proofs on the same nodes serving the primary inference load if low latency is critical. Instead, use asynchronous verification: serve the raw output immediately while the proof is generated in the background. If the proof fails to verify, you can then trigger a re-inference from a different node. This "prove later" approach maintains user experience while preserving the security guarantees of the network.
Node Collusion and Incentive Misalignment
In a decentralized network, the risk of collusion is higher than in centralized systems because nodes are economically motivated to minimize costs. If the reward for providing a proof is fixed and low, nodes may collude to share computational shortcuts or simply report false proofs to collect rewards. This is particularly dangerous in systems relying on lightweight verification, where a small number of malicious nodes can skew results without detection.
To prevent this, ensure the verification mechanism requires diverse, independent computation. Use protocols that mandate multiple independent nodes to generate proofs for the same input, then cross-check them. If the proofs do not match, the system should automatically reject the result and penalize the offending nodes. This "majority wins" approach forces collusion to be economically unviable, as the cost of coordinating multiple honest nodes exceeds the potential reward.
Integration Complexity with Existing LLM Stacks
Integrating verifiable inference into legacy LLM pipelines often feels like trying to fit a square peg into a round hole. Most existing LLM frameworks assume a trusted, single-source provider. They do not natively handle the asynchronous nature of proof generation or the need to validate cryptographic signatures before accepting output. This leads to integration headaches, where developers must write custom middleware to bridge the gap between their application logic and the decentralized verification layer.
Start by abstracting the inference provider behind a unified interface. This allows you to swap out the decentralized node for a centralized one during development and testing without rewriting your core logic. Use a wrapper that accepts standard LLM inputs and returns a structured response containing both the output and the verification proof. This approach minimizes refactoring effort and makes it easier to debug issues that arise from the verification layer rather than the model itself.
No comments yet. Be the first to share your thoughts!