The shift to distributed compute
Decentralized inference represents a structural break from the centralized cloud model that has dominated large language model (LLM) deployment for the past decade. Traditional cloud inference relies on vertically integrated providers who control the hardware, the networking layer, and the pricing. While this model offers simplicity, it creates a bottleneck where cost and latency are dictated by a few major hyperscalers. The emerging decentralized network approach treats GPU compute as a liquid commodity, aggregating idle consumer and data-center hardware into a unified inference layer.
The technical challenge of decentralized inference has historically been latency. Inference requires low-latency responses, often under 100 milliseconds, which is difficult to achieve when requests must traverse a distributed network of untrusted nodes. Early attempts at distributed training succeeded because they could tolerate high latency; inference cannot. New architectures address this by combining sharding techniques with zero-knowledge (ZK) proofs. Sharding allows a single inference request to be split across multiple nodes, while ZK proofs ensure that each node has executed the correct computation without revealing the model weights or the input data.
Projects like Prime Intellect are engineering stacks specifically for this constraint, aiming to deliver consumer-GPU-grade performance at public network latencies. By removing the monopoly on hardware access, decentralized inference markets create a competitive pressure that forces traditional cloud providers to lower prices and improve efficiency. This shift is not just about cost; it is about resilience. A distributed inference network is inherently more robust against single-point failures and regional outages than a centralized cloud region.
The following chart illustrates the cost-per-token trajectory for decentralized GPU networks compared to traditional cloud providers over the last 12 months, highlighting the widening efficiency gap.
Verifying results without trust
The core technical challenge of decentralized inference is ensuring output correctness when the underlying hardware is untrusted. Unlike traditional cloud providers, decentralized networks rely on nodes that may behave deceitfully, creating a threat model where the integrity of the computation must be verified rather than assumed [src-serp-6]. To solve this, the ecosystem has converged on three primary mechanisms: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic staking.
Zero-knowledge proofs (ZKPs) offer the strongest security guarantee by mathematically proving that the inference was executed correctly without revealing the underlying data. While this eliminates the need to trust the node operator, the computational overhead remains prohibitively high for large language models, often making verification slower than the original inference itself. This latency bottleneck currently limits ZKPs to smaller models or specific, constrained inference tasks.
Optimistic fraud proofs take a different approach by assuming correctness unless challenged. A node submits its result, and a dispute window opens for other participants to submit a fraud proof if they detect an error. This method significantly reduces latency and computational overhead compared to ZKPs, making it more viable for current decentralized inference workloads, though it introduces a delay for finality while disputes are resolved.
Cryptoeconomic staking relies on financial incentives rather than pure cryptography. Nodes must stake collateral; if they provide incorrect results, they lose their stake (slashing). This approach is efficient and low-latency but relies on the assumption that the economic penalty outweighs the potential profit from cheating, which requires a sufficiently large and active network of verifiers.
| Mechanism | Computational Overhead | Latency Impact | Security Guarantee |
|---|---|---|---|
| Zero-Knowledge Proofs | Very High | High | Cryptographic |
| Optimistic Fraud Proofs | Low | Medium | Economic + Cryptographic |
| Cryptoeconomic Staking | Low | Low | Economic |
Network Latency in Decentralized Inference
The primary bottleneck for decentralized inference is not compute power, but network latency. When a model is split across multiple nodes, the time it takes for data to travel between them often exceeds the time required for the actual computation. This creates a hard ceiling on performance for real-time applications, where every millisecond counts.
To mitigate this, the industry is moving toward model sharding and edge computing. Model sharding involves partitioning a deep neural network into fixed blocks of layers, allowing different nodes to handle specific parts of the inference process [src-4]. This approach reduces the data transfer volume between nodes compared to sending full inputs to a single remote server. However, it introduces synchronization overhead that must be carefully managed.
Edge computing complements sharding by processing data closer to the source. By keeping inference tasks within local networks or on-device, the round-trip time to distant data centers is eliminated. This is critical for maintaining the low-latency requirements of interactive AI services.
Projects like Prime Intellect are engineering distributed inference stacks specifically to target the 100ms latencies of the public internet, proving that consumer GPUs can compete when network constraints are addressed [src-2]. The future of decentralized inference lies in balancing these network realities with computational efficiency.
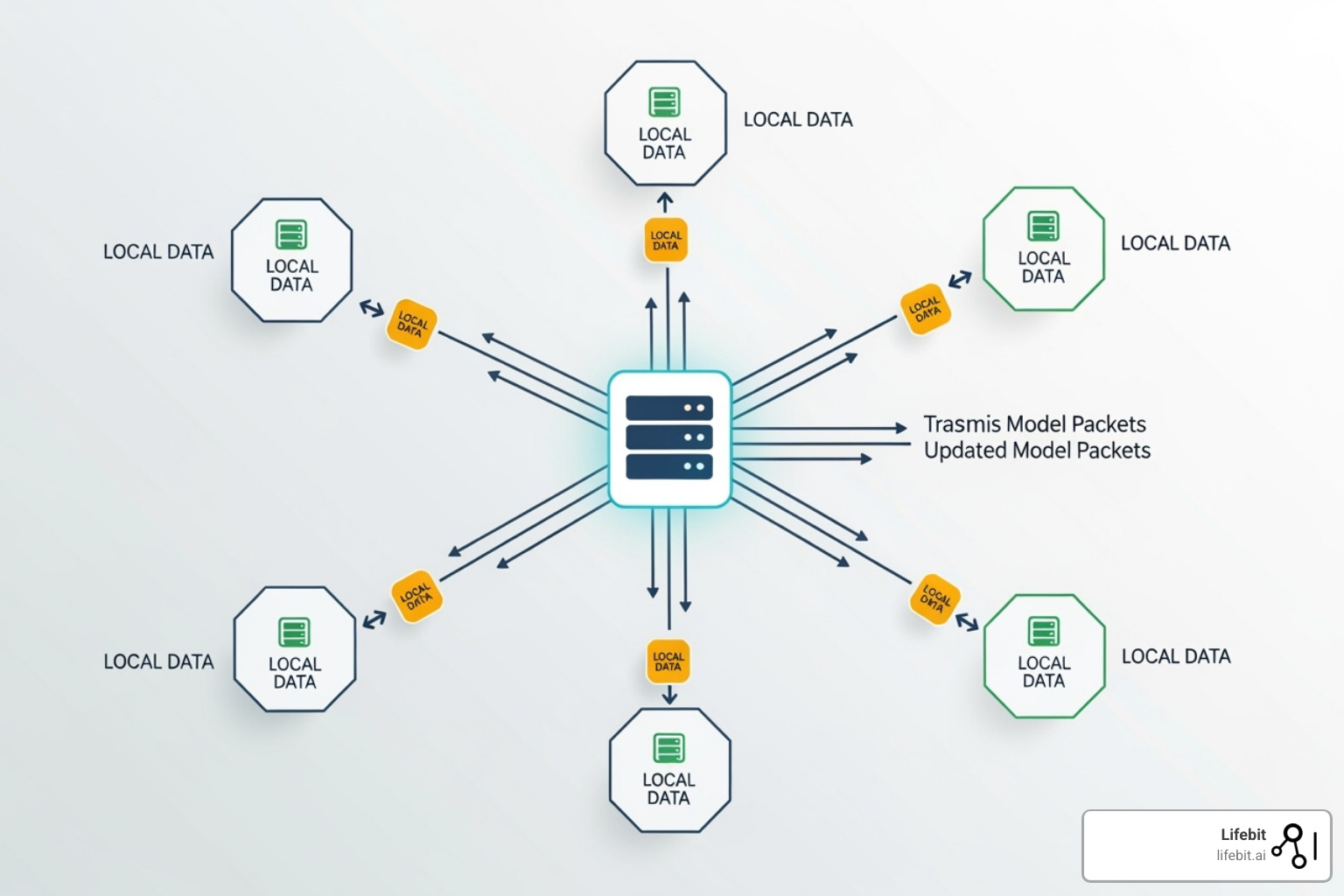
Key Players and Market Dynamics
The decentralized inference landscape is defined by two primary architectural approaches: sharding large models across distributed nodes and leveraging dual-layer structures to balance compute with verification. Providers are competing not just on raw GPU availability, but on their ability to minimize latency while maintaining cryptographic proof of execution.
Protocol Architecture
Leading networks like Wavefy utilize a sharding mechanism to split large language models across multiple participants. This approach reduces the hardware barrier to entry, allowing smaller GPU providers to contribute to a unified inference pool. By distributing the model weights, these protocols achieve cost efficiencies that centralized cloud providers struggle to match, particularly for high-throughput workloads.
Other entrants are exploring dual-layer architectures. These systems separate the initial token generation from the final verification step. This design allows for rapid inference on edge devices while reserving heavier computational verification for more powerful nodes, ensuring that the decentralized network remains both fast and secure.

Market Positioning and Cost
The economic advantage of decentralized inference lies in its utilization of underused GPU capacity. By aggregating idle resources from global providers, these markets offer inference rates significantly lower than traditional cloud APIs. This cost structure is attracting developers who require scalable, low-latency access to large models without the overhead of dedicated infrastructure.
Choosing a decentralized provider
Selecting the right decentralized inference provider requires balancing latency constraints against cost efficiency. Unlike centralized clouds, decentralized networks introduce variable latency due to node distribution and consensus mechanisms. Developers must evaluate whether the network can guarantee sub-100ms response times for interactive applications or if it suits batch processing workloads.
Evaluate verification mechanisms
Security in decentralized inference relies on verifiable computation. Providers typically use zero-knowledge proofs (ZK-SNARKs) or optimistic fraud proofs to ensure node outputs are correct. ZK proofs offer immediate finality but incur higher computational overhead. Fraud proofs are cheaper but require a challenge period, delaying result availability. Choose based on your tolerance for latency versus security assurance.
Assess network latency and stability
Node heterogeneity is a primary risk factor. Consumer-grade GPUs may offer low costs but suffer from inconsistent uptime and variable performance. Enterprise-grade nodes provide stability but at a premium. Look for providers with Service Level Agreements (SLAs) that define maximum latency thresholds and uptime guarantees. Test with small batches to measure real-world p99 latency across different regions.
Review tokenomics and economic incentives
The economic model dictates provider reliability. Providers with stable tokenomics and robust staking mechanisms are less likely to act maliciously or exit abruptly. Check the bond size required for node operators; higher stakes often correlate with better reliability. Avoid networks with hyperinflationary token emissions that could devalue rewards and destabilize the ecosystem.
Conduct a pilot test
Before committing to production, run a pilot test. Send a representative sample of inference requests to the network. Monitor latency, error rates, and cost consistency. Compare the results against your baseline centralized provider. This step is critical for validating that the decentralized solution meets your specific technical requirements.
Common questions about decentralized inference
Is decentralized inference secure? Security relies on cryptographic verification rather than trust. The ecosystem uses three main approaches: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics to ensure nodes behave honestly [[src-serp-3]].
How does latency compare to AWS? Latency is currently higher due to consensus and verification overhead. While AWS offers direct access, decentralized networks introduce slight delays to aggregate proofs across the sharded GPU grid [[src-serp-6]].
What models are supported? Most networks support standard transformer architectures. As zero-knowledge proof efficiency improves, support is expanding to larger language models and diffusion networks [[src-serp-3]].
No comments yet. Be the first to share your thoughts!