The bottleneck in centralized AI compute
Centralized cloud providers are hitting a hard ceiling. As demand for AI inference scales, the existing infrastructure is struggling to keep pace. AWS controls 32% of the global cloud market, creating a concentrated bottleneck where pricing power rests with a handful of tech giants. This oligopoly limits competition and drives up costs for developers who need scalable, low-latency inference capabilities.
The market reality is stark. The AI inference server market is projected to reach USD 35.9 billion by 2030, growing at a CAGR of 18.2% from USD 11.3 billion in 2023. This explosive growth is outstripping the capacity of traditional centralized data centers. The $106 billion AI inference market is about to experience its biggest disruption yet, driven by the physical and economic limits of centralized compute.
Decentralized inference markets emerge as the structural solution to this constraint. By distributing compute across a global network of idle GPUs, these protocols bypass the single-point failures and pricing rigidity of big tech. This shift transforms inference from a scarce, centrally controlled resource into a liquid, accessible commodity.
How decentralized inference markets operate
Decentralized inference markets function as distributed compute exchanges, aggregating idle GPU capacity from global providers to serve AI workloads. Unlike traditional cloud providers that rely on centralized data centers, these networks leverage blockchain-based protocols to verify compute integrity and route tasks to available nodes. This architecture reduces latency for end-users while lowering costs for model providers by utilizing underutilized hardware.
The process begins with task fragmentation and distribution. When a user submits an inference request—such as generating text or running a vision model—the protocol breaks the computation into smaller, verifiable chunks. These chunks are broadcast to a network of node operators who have staked collateral to guarantee performance. This distribution allows the network to scale horizontally, drawing from a pool of consumer-grade and enterprise GPUs rather than a single data center.
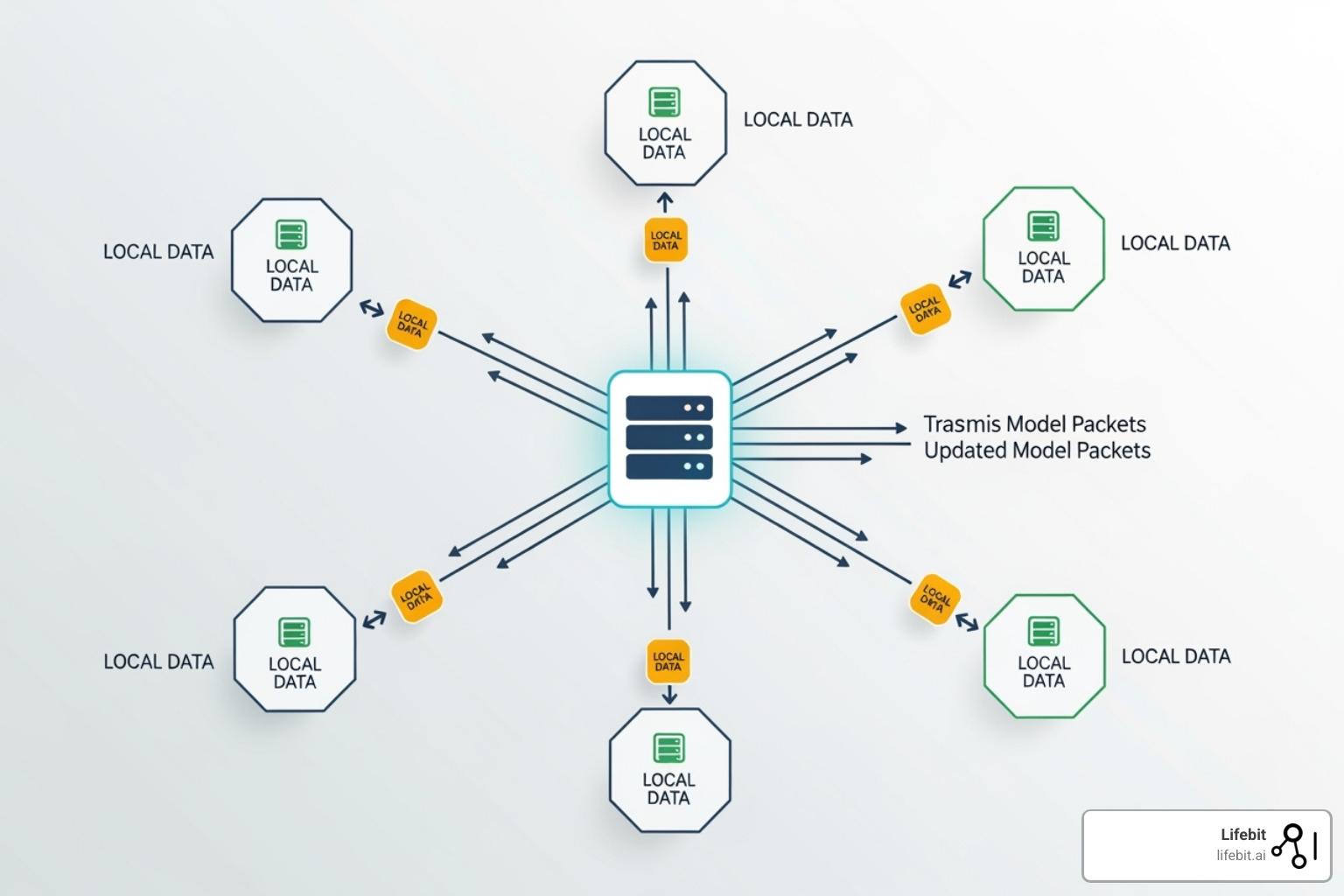
Node operators process the fragmented tasks using their local hardware. To prevent fraud or incorrect outputs, the protocol employs verifiable computation techniques, such as zero-knowledge proofs or result replication, where multiple nodes independently solve the same chunk. The network reaches consensus on the correct output before it is returned to the user, ensuring reliability without a central authority.
Once the correct inference is verified, smart contracts automatically settle payments. Node operators receive cryptocurrency rewards proportional to their computational contribution, while users pay fees that are often lower than centralized equivalents. This automated settlement removes intermediaries, creating a transparent market where compute supply and demand are matched in real-time.
Advanced networks implement edge-routing strategies to minimize latency. By prioritizing nodes geographically close to the user or those with the lowest current load, these markets can achieve response times competitive with major cloud providers. This optimization is critical for real-time applications, such as interactive AI agents, where delays directly impact user experience.
The technical tradeoff involves balancing decentralization with performance. While distributed networks offer superior resilience and cost efficiency, they must overcome the overhead of consensus mechanisms and network latency. Protocols like Prime Intellect and Indium are addressing these challenges by optimizing their distributed inference stacks for consumer GPUs, aiming to deliver sub-100ms latency for public-facing applications. This shift enables a more democratized AI infrastructure, where compute power is no longer bottlenecked by a few major tech giants.
Key players in the distributed compute landscape
The infrastructure layer for decentralized inference markets is consolidating around three primary protocols: Bittensor, PAI3 (formerly Gensyn), and Prime Intellect. Each network adopts a distinct architectural philosophy regarding how to aggregate idle GPU capacity and distribute inference tasks. While they share the goal of reducing reliance on centralized cloud providers, their approaches to consensus, latency, and tokenomics differ significantly.
Bittensor operates as a competitive market where "miners" (GPU providers) compete to provide the best inference results. This structure drives down costs through market pressure but introduces complexity in verifying output quality without introducing significant latency. PAI3 focuses on verifiable computation, using cryptographic proofs to ensure that the inference was performed correctly before payment is released. Prime Intellect takes a more direct approach, acting as a marketplace that aggregates consumer-grade GPUs to serve enterprise-level inference demands with a focus on low-latency delivery.
The following table compares the core technical and economic metrics of these protocols. Note that latency figures are estimates based on public documentation and network conditions as of late 2024.
| Protocol | Consensus Mechanism | Target Latency | Primary Use Case |
|---|---|---|---|
| Bittensor | Yuma Consensus (Competitive) | Variable (100ms+) | General-purpose AI model serving |
| PAI3 | Verifiable Computation (ZK Proofs) | High (Optimized for correctness) | High-stakes, auditable inference |
| Prime Intellect | Direct Marketplace Aggregation | Low (<100ms) | Consumer GPU aggregation for enterprise |
Bittensor's Yuma Consensus rewards miners based on the perceived value of their output, creating a self-regulating ecosystem where better models and faster inference naturally rise to the top. However, this competitive model can lead to fragmentation if not carefully managed. PAI3's emphasis on verifiability makes it suitable for applications where computational integrity is paramount, such as financial modeling or scientific research, though the overhead of proof generation can impact speed. Prime Intellect prioritizes accessibility, leveraging the vast pool of underutilized consumer hardware to offer competitive pricing, making it an attractive entry point for developers seeking cost-effective inference solutions.
Reliability and Latency in Decentralized Inference Markets
The primary constraint facing decentralized inference markets is the inherent latency of distributed networks compared to dedicated data centers. While centralized providers operate within controlled environments with predictable network paths, decentralized stacks must route requests across heterogeneous consumer-grade hardware and varying internet backbones. This introduces variability that can degrade the user experience, particularly for applications requiring real-time interaction.
To mitigate this, leading protocols are engineering distributed inference stacks specifically designed to meet the latency expectations of public-facing applications. For instance, Prime Intellect has outlined a distributed inference stack engineered for consumer GPUs, explicitly targeting the 100ms latency threshold required for responsive user interfaces. This target serves as a critical benchmark, distinguishing viable production-ready systems from experimental prototypes that cannot handle the jitter of public internet traffic.
Achieving this performance requires a dual-layer architecture. The first layer handles request orchestration and load balancing, ensuring tasks are routed to nodes with sufficient compute and low network distance. The second layer manages the actual inference execution, often leveraging optimized model quantization to reduce computational overhead. Without this architectural sophistication, the cost advantages of decentralized compute are negated by the poor performance and high failure rates associated with unoptimized distributed routing.
The tradeoff is clear: while centralized data centers offer superior consistency, decentralized markets provide economic efficiency and resilience. The viability of decentralized inference markets hinges on whether protocol-level optimizations can consistently bridge the gap between theoretical throughput and actual end-to-end latency. Current evidence suggests that with proper stack engineering, the 100ms target is achievable, but it remains the primary technical hurdle for widespread adoption in latency-sensitive applications.
Market adoption signals for 2026
The trajectory for decentralized inference markets is shifting from experimental prototypes to production-grade infrastructure. The AI inference market, currently valued at approximately $106 billion, faces a supply constraint that centralized cloud providers are struggling to meet. As demand for inference compute rises—potentially up to a billion times according to industry projections—the economic incentive to diversify compute sources becomes a structural necessity rather than a speculative bet.
Investment flows are beginning to reflect this technical maturity. Capital is moving away from pure token speculation toward protocols that demonstrate actual compute utilization and reliable latency. This shift indicates that early adopters are validating decentralized networks for real-world workloads, particularly in regions or use cases where data sovereignty or cost-efficiency outweighs the slight overhead of distributed verification.
Real-time market sentiment
Tracking the price action of major decentralized AI tokens provides a pulse on market sentiment. While token prices do not directly measure compute throughput, sustained trading volume and price stability often correlate with increased protocol activity and developer interest.
Checklist for evaluating decentralized inference markets
Assessing the viability of a decentralized inference market requires moving beyond tokenomics to examine the underlying technical infrastructure. Investors and developers must verify that the protocol can reliably handle compute loads without the latency penalties common in distributed networks. The following criteria provide a framework for evaluating these systems against established cloud standards.
1. GPU Uptime and Availability
Verify that node operators maintain high availability SLAs. Decentralized networks often struggle with node churn; look for protocols with staking mechanisms or slashing conditions that penalize downtime. A reliable network requires consistent compute availability, not just theoretical capacity.
2. Verification Mechanisms
Evaluate how the network proves computation was completed correctly. Zero-knowledge proofs or optimistic verification are essential to prevent fraud. Without robust verification, the cost savings of decentralized inference are negated by the risk of corrupted outputs or malicious actors.
3. Latency SLAs
Compare the network’s average response times against centralized cloud providers. Prime Intellect and similar stacks target sub-100ms latencies for real-time applications. If the protocol cannot guarantee low latency, it remains limited to batch processing rather than interactive AI services.
4. Token Liquidity
Assess the depth of the token market. Low liquidity creates slippage risks for large compute purchases and reduces the stability of node rewards. A healthy decentralized inference market requires sufficient trading volume to support both infrastructure investment and user transactions.
Frequently Asked Questions About Decentralized Inference Markets
These answers address common queries regarding the structure, reliability, and technical feasibility of decentralized inference markets. The focus is on concrete mechanics rather than speculative hype.
No comments yet. Be the first to share your thoughts!