The economics of decentralized inference
Centralized AI providers face mounting pressure as compute demand outpaces supply, creating a structural arbitrage opportunity for distributed networks. The cost of running large language models in centralized data centers is rising sharply, driven by hardware scarcity and energy constraints. Decentralized inference offers a path to lower costs by aggregating unused GPU capacity from a global pool of providers, effectively turning idle hardware into a liquid, on-demand resource.
This shift is not merely about cost reduction; it is about architectural resilience. By fragmenting compute across thousands of nodes, decentralized networks mitigate the single points of failure inherent in centralized clouds. The market is currently valuing this utility through tokens like RENDER and AKT, which serve as the financial rails for these transactions.
Verification remains the core technical challenge. Unlike simple data storage, AI inference requires ensuring the computation was actually performed correctly. Research from Dragonfly highlights three emerging approaches: zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic incentives. Each method balances trust minimization against latency and cost, a trade-off that will define the competitive landscape over the next two years.
The transition from experimental protocols to production-grade infrastructure is accelerating. Projects like Prime Intellect are already building stacks designed for consumer-grade GPUs, aiming to achieve the sub-100ms latencies required for real-time applications. This democratization of compute power is reshaping the valuation metrics for AI infrastructure, moving the focus from proprietary hardware ownership to network accessibility and verification reliability.
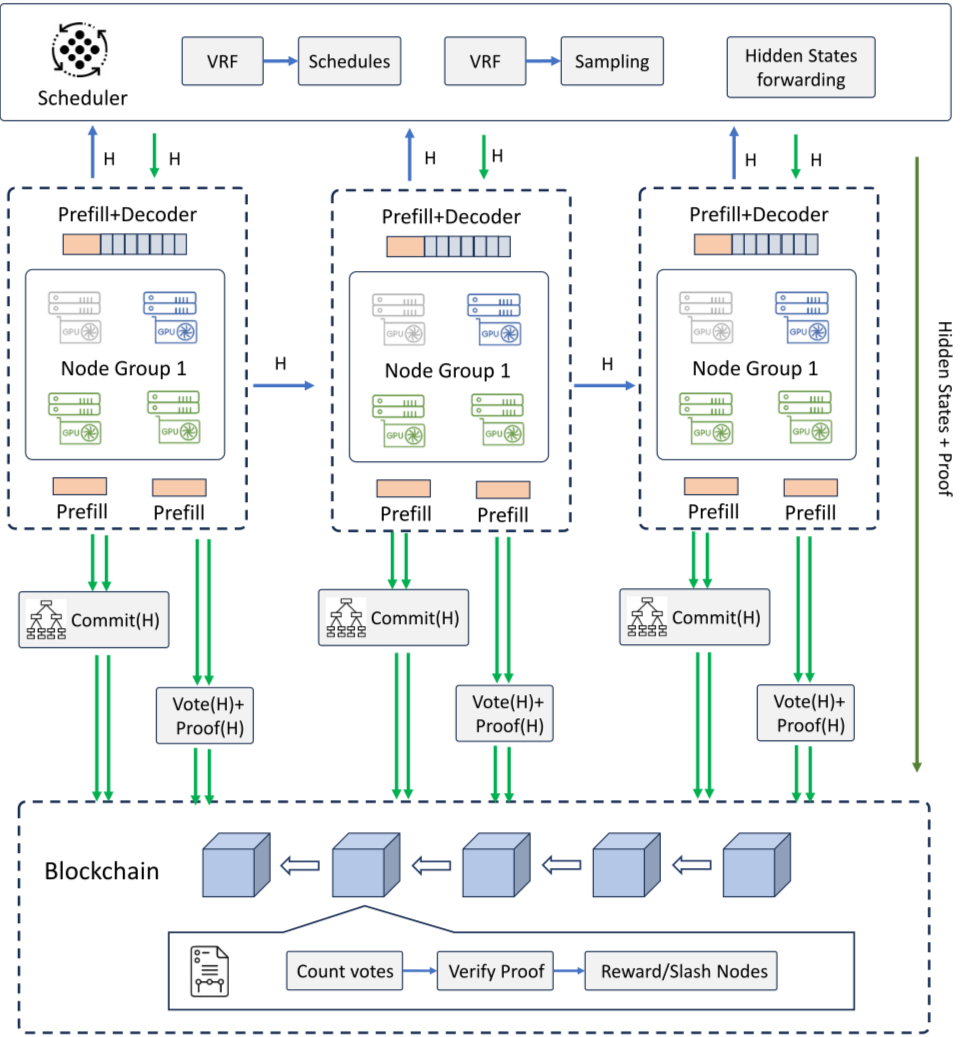
Distributed Inference Architecture
Decentralized inference shifts execution from monolithic data centers to a mesh of heterogeneous devices. This architectural pivot relies on three core mechanisms: model sharding to manage memory constraints, latency optimization to maintain throughput, and cryptographic verification to ensure computational integrity.
Model Sharding and Layer Partitioning
Large language models (LLMs) exceed the memory capacity of individual edge devices. To solve this, systems partition neural networks into fixed blocks of layers. According to IEEE research on decentralized model distribution, these blocks are routed across the network based on available compute resources. This allows a single inference request to be processed by multiple nodes working in parallel, effectively aggregating their VRAM to handle models that would otherwise be inaccessible.
Latency Handling in Mesh Networks
Distributing compute introduces network overhead. To mitigate this, decentralized inference engines employ dynamic routing protocols that select the lowest-latency paths for tensor transmission. The architecture prioritizes nodes with stable connections and sufficient idle capacity, ensuring that the distributed workload completes within acceptable timeframes. This requires sophisticated orchestration to balance the trade-off between computational load and network speed.
Verification and Integrity
Trustless execution demands proof that computations were performed correctly without exposing proprietary model weights. Systems utilize zero-knowledge proofs (ZKPs) or similar cryptographic commitments to verify that a node’s output matches the expected mathematical result of the assigned layer block. This verification layer is critical for financial-grade applications, ensuring that the decentralized network provides reliable, tamper-proof results.
Market Context
The transition to decentralized inference is reflected in the valuation of underlying infrastructure tokens. The following chart visualizes the technical trends and volatility in the AI compute sector, highlighting the market’s response to these architectural shifts.

Trust mechanisms for decentralized inference
Enterprise adoption of decentralized inference hinges on cryptographic proof rather than institutional reputation. In these trustless environments, computing nodes may behave deceitfully, creating a threat model where result integrity is the primary asset to protect. Without verifiable mechanisms, the computational overhead of AI inference becomes a liability rather than a utility.
Three main approaches have emerged to address this friction: zero-knowledge proofs (ZK), optimistic fraud proofs, and cryptoeconomic incentives. Each method balances verification speed, computational overhead, and security assumptions differently, requiring market participants to select the architecture that aligns with their risk tolerance and latency requirements.
| Method | Verification Speed | Computational Overhead | Security Assumption |
|---|---|---|---|
| Zero-Knowledge Proofs | Slow | High | Mathematical |
| Fraud Proofs | Fast | Low | Game Theoretic |
| Cryptoeconomics | Medium | Medium | Bonded Stakes |
Zero-knowledge proofs offer the highest level of security by allowing a prover to demonstrate the validity of an inference result without revealing the underlying data or model weights. This mathematical guarantee is essential for high-value financial applications but incurs significant computational overhead, often making real-time inference prohibitively expensive. Optimistic fraud proofs, by contrast, assume results are valid unless challenged. This approach drastically reduces overhead and increases speed, relying on a window of time for validators to detect and dispute fraudulent outputs.
Cryptoeconomic incentives bridge the gap by using bonded stakes and slashing conditions to deter malicious behavior. While less mathematically rigorous than ZK proofs, this method is currently the most scalable for large-scale decentralized inference networks. The choice between these mechanisms defines the trade-off between absolute certainty and operational efficiency in the emerging AI compute market.
Integrate decentralized inference workflows
Adopting decentralized inference requires treating compute as a variable cost rather than a fixed infrastructure burden. Developers must shift from monolithic model hosting to modular API integration, selecting providers that balance latency, verification, and price volatility. This section outlines the operational steps to embed these services into production pipelines.
Begin by identifying providers that expose standard REST or gRPC interfaces. Look for stacks designed for low-latency consumer GPU access, such as Prime Intellect’s distributed inference network, which targets 100ms response times. Verify that the API supports parallel request routing to avoid single points of failure.
Ensure the provider uses cryptographic proofs or verifiable execution environments. Frameworks like VeriLLM allow for lightweight verification of inference results, ensuring that the output matches the computed hash. Without this, you risk integrating unverified or manipulated model outputs into your application.

Run load tests against the selected endpoints to measure p95 latency under concurrent load. Compare the cost per million tokens against centralized alternatives like AWS Bedrock or Azure AI. Decentralized markets often offer lower baseline costs but may exhibit higher variance during peak network congestion.

Build a circuit breaker pattern that switches to a centralized provider if the decentralized network exceeds your latency threshold. This ensures service continuity when network participation drops or computational demand spikes unexpectedly.
| Provider | Avg Latency | Proof Type |
|---|---|---|
| Prime Intellect | ~100ms | ZK-Rollups |
| Wavefy | Variable | Sharding |
| Centralized Cloud | <50ms | None |
The integration cost of decentralized inference is not just financial; it is architectural. By treating compute as a liquid asset, you gain exposure to market efficiencies but must manage the operational complexity of distributed nodes. Start with a hybrid approach, routing non-critical inference tasks to decentralized markets while keeping core services on reliable centralized infrastructure.
Frequently asked questions about decentralized inference
Decentralized inference addresses the bottleneck of centralized compute by distributing model execution. This section clarifies how crypto incentives align with technical execution and verification.
| Feature | Centralized | Decentralized |
|---|---|---|
| Compute Source | Single Cloud Provider | Distributed GPU Network |
| Verification | Trusted Provider | Zero-Knowledge Proofs |
| Latency | Low (10-50ms) | Higher (100ms+) |
The shift toward decentralized inference introduces new verification mechanisms. While centralized systems rely on trust, decentralized networks use cryptographic proofs to ensure computational integrity, a critical requirement for high-stakes financial applications.
No comments yet. Be the first to share your thoughts!