Why use decentralized inference markets
Switching from centralized cloud providers to decentralized inference markets is primarily an economic and technical adjustment. You are trading the convenience of a single vendor for access to a distributed pool of compute resources. This shift allows you to bypass the bottlenecks that often plague centralized infrastructure, specifically regarding cost and latency.
The economic argument is straightforward. Centralized providers often operate with significant markup and limited capacity during peak demand. Decentralized networks aggregate idle or underutilized GPUs from a global network. This competition among node operators drives prices down, often significantly below the standard rates of major cloud providers. For projects running high-volume inference tasks, these savings compound quickly.
Latency is the technical counterweight. While distributed systems can introduce network overhead, modern decentralized inference protocols optimize for low-latency retrieval. By connecting to nodes geographically closer to your end-users, you can reduce the round-trip time for AI predictions. This is particularly useful for real-time applications where every millisecond counts.
The market is responding to this demand. Research projects the AI inference server market to reach USD 35.9 billion by 2030, up from USD 11.3 billion in recent years, driven largely by the need for scalable, cost-effective compute solutions [[src-serp-5]]. Understanding these dynamics helps you decide when and how to access these markets effectively.
Choose the right inference network
Selecting a decentralized inference network requires balancing three competing factors: latency requirements, GPU availability, and the security model you trust. Unlike centralized cloud providers, these markets distribute workloads across independent nodes, meaning your choice of platform directly dictates performance reliability and cost efficiency.
Start by defining your latency tolerance. If you are building a real-time application, such as an interactive chatbot or live video analysis, you need networks optimized for speed. Prime Intellect, for example, engineers its stack specifically for consumer GPUs to achieve latencies around 100ms, making it suitable for public-facing, low-delay tasks. In contrast, if your workload involves batch processing or non-interactive model serving, you can prioritize cost savings over speed, often accepting higher latency in exchange for significantly lower compute prices.
Next, evaluate the consensus mechanism and verification layer. Decentralized inference relies on nodes proving they executed the computation correctly. Some networks use zero-knowledge proofs (ZKPs) to verify outputs, which adds computational overhead but ensures cryptographic security. Others use reputation systems or slashing conditions, where node operators stake tokens that can be forfeited if they provide incorrect results. Choose a network whose verification method aligns with your risk appetite; ZKPs offer stronger guarantees but may increase inference time, while reputation-based systems are faster but rely on economic incentives to deter bad actors.
Finally, assess GPU availability and network decentralization. A network with a large pool of diverse GPU types (e.g., NVIDIA A100s, H100s, or consumer RTX cards) offers better resilience and pricing flexibility. However, highly decentralized networks may have higher overhead due to node coordination. Use the comparison below to weigh these trade-offs against your specific project needs.
| Network | Typical Latency | Primary GPU Type | Verification Model |
|---|---|---|---|
| Prime Intellect | ~100ms | Consumer & Pro GPUs | Reputation & Slashing |
| PAI3 | Low (Variable) | Distributed GPUs | Consensus Protocol |
| Io.net | Low-Medium | Consumer GPUs | Proof of Work |
| Akash | Medium | Diverse Cloud GPUs | Smart Contracts |
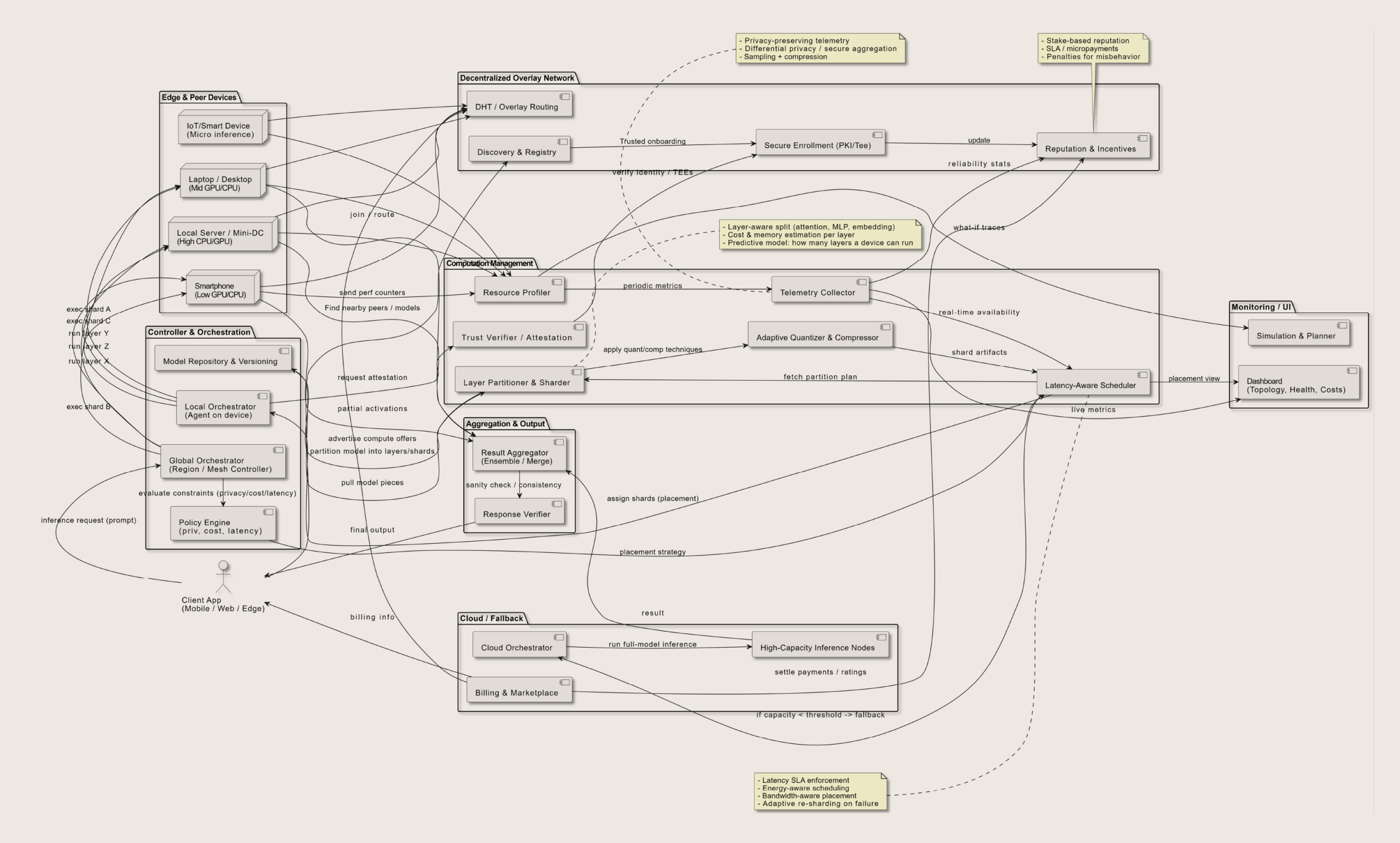
Prepare your model for distributed nodes
Before deploying to a decentralized inference market, your model must be optimized for heterogeneous hardware. Unlike centralized cloud instances that offer uniform GPU power, decentralized networks consist of diverse consumer-grade GPUs with varying VRAM and compute capabilities. To ensure low-latency performance and minimize costs, you need to format your artifacts so they run efficiently across this fragmented infrastructure.
Start by reducing the precision of your model weights. Quantization compresses the model from 16-bit floating point (FP16) to 8-bit (INT8) or even 4-bit (INT4). This step is critical for decentralized nodes because it significantly reduces VRAM requirements, allowing smaller consumer GPUs to load and run larger models. Platforms like Prime Intellect rely on this efficiency to maintain the 100ms latency targets required by public inference requests.
Bundle your quantized weights with the necessary tokenizer files and inference engine configurations. The packaging format must be lightweight and easily verifiable. Ensure that your configuration files explicitly state the required hardware specifications, such as minimum VRAM and supported CUDA versions, so the network can match your model to compatible nodes. This prevents deployment failures on nodes that lack the necessary compute power.
Upload your packaged artifacts to a decentralized storage network like IPFS or Arweave. This ensures that your model weights are immutable and globally accessible without relying on a single cloud provider. The network nodes will fetch these artifacts from the storage layer when executing inference tasks. Use a content identifier (CID) to reference your model, which allows the verification layer to confirm that the weights haven't been tampered with during transit.
Submit your model to the decentralized inference market by registering the CID and setting your pricing parameters. The network’s consensus protocol will then distribute inference tasks to nodes that have downloaded your artifacts. Monitor the initial deployment to ensure nodes are successfully verifying and executing your model. Adjust your quantization level or pricing if you notice high rejection rates or latency spikes from specific node types.
By following these steps, you align your model with the technical realities of decentralized compute. This preparation reduces the risk of failed inferences and ensures that your AI service remains cost-effective and responsive across the network.
Verify node performance and trust
Before committing compute resources to a decentralized market, you must audit the node provider’s reliability. Unlike centralized cloud providers, decentralized networks rely on consensus and cryptographic proofs rather than service level agreements. Your goal is to filter out low-quality nodes that might return incorrect outputs or suffer from high latency, which can break real-time inference pipelines.
Start by checking the node’s historical uptime and response times. Platforms often display node reputation scores based on past task completion. Look for nodes with consistent performance metrics rather than those that spike occasionally. A node that frequently drops connections or returns timeout errors will degrade your application’s user experience, regardless of its low price.
Next, verify the integrity of the inference results. For high-stakes applications like financial modeling or risk assessment, verifiable inference is mandatory to prevent fraud. Some networks use zero-knowledge proofs or multi-node consensus to validate outputs. Ensure the platform you are using offers a mechanism to double-check results, such as having multiple nodes compute the same task and comparing their outputs. If a node returns a result that deviates significantly from the consensus, flag it for removal.
Finally, consider the node’s hardware specifications. Inference tasks are sensitive to latency, and a node with outdated GPUs may struggle to meet performance requirements. Check if the node provider publishes their hardware specs and whether they undergo regular audits. Combining hardware verification with output validation gives you a robust framework for selecting trustworthy node providers.
Deploy and monitor inference tasks
Launching a task on decentralized inference markets requires precise configuration to balance cost with reliability. Start by selecting your model format and setting a strict budget cap. Most platforms allow you to define a maximum price per token, which prevents runaway costs if node prices spike during high demand.
Once the task is submitted, monitor latency and throughput in real-time. Decentralized networks can suffer from node dropout, so configure your client to request redundant proofs or fallback nodes if the primary provider fails to respond within your SLA. Tools like Prime Intellect offer dashboards that visualize node performance, helping you identify slow or unresponsive providers before they impact your application.
Verification is the final layer of security. Ensure your integration checks the cryptographic proof returned by the node against the original request. This step confirms that the computation was actually performed and wasn't skipped or tampered with. Without this verification, you risk paying for invalid results.
Pre-deployment checklist
-
Model format compatible with target nodes (e.g., GGUF, ONNX)
-
Budget cap set per token or per task
-
Latency SLA defined with fallback node options
-
Verification mechanism enabled for proof checking
No comments yet. Be the first to share your thoughts!