Why decentralized inference matters now
The shift toward decentralized inference markets addresses two critical bottlenecks in the current AI landscape: prohibitive costs and data privacy concerns. Centralized cloud providers dominate the inference landscape, creating single points of failure and restricting where sensitive data can be processed. Decentralized networks distribute this computational load across a global pool of nodes, offering a more resilient and economical alternative.
Cost efficiency is the primary driver for this transition. By leveraging underutilized GPU capacity from individual providers and small data centers, decentralized markets significantly undercut the pricing models of major cloud vendors. This arbitrage allows developers to run large language models and image generation tasks at a fraction of the traditional cost, making advanced AI accessible to smaller teams and independent researchers.
Data sovereignty is equally important. In a centralized model, data must often be sent to specific geographic regions or proprietary servers, raising compliance and security questions. Decentralized inference allows data to remain closer to the source or be processed in encrypted shards across multiple jurisdictions, ensuring that sensitive information does not leave the control of the owner.
The market momentum is clear. According to industry projections, the AI Inference Server Market is expected to reach $35.9 billion by 2030, driven largely by the need for scalable, cost-effective inference solutions. Decentralized networks are positioning themselves as the infrastructure layer for this growth, offering a transparent and competitive ecosystem for AI computation.
Choose the right decentralized network
Selecting a decentralized inference market requires matching your latency tolerance and security needs to the underlying architecture. Not all networks handle GPU distribution equally. Some prioritize raw throughput for consumer-grade hardware, while others focus on cryptographic verification for sensitive workloads.
Start by evaluating three core factors: latency, GPU availability, and the security model. The table below compares leading protocols based on these metrics.

| Network | Target Latency | Primary GPU | Security Model |
|---|---|---|---|
| Prime Intellect | ~100ms | Consumer GPUs | Cryptographic proofs |
| PAI3 | Low | Enterprise & Consumer | Dual-layer architecture |
| Wavefy | Variable | Specialized Clusters | Consensus-based |
| Indium | Low | Heterogeneous | Zero-knowledge proofs |
Prime Intellect focuses on consumer GPUs to keep costs down, aiming for 100ms latencies suitable for public-facing applications. PAI3 and Indium utilize dual-layer architectures to balance scalability with security, often leveraging enterprise-grade hardware for heavier loads. Wavefy’s approach varies based on cluster availability, making it less predictable for real-time tasks.
Your choice depends on whether you prioritize speed or verification. For real-time chat or interactive apps, low-latency consumer networks like Prime Intellect are often sufficient. For financial or healthcare data, the cryptographic guarantees of PAI3 or Indium provide necessary safeguards.
Deploy models using the Steps workflow
Deploying to decentralized inference markets requires a precise sequence: selecting a node, uploading the model, configuring the API, and verifying inference. Unlike centralized cloud providers, you are coordinating with a distributed network of independent compute providers.
The process moves from technical preparation to live validation. Each step ensures your model runs efficiently across the network while maintaining the security and cost benefits that define decentralized inference markets.
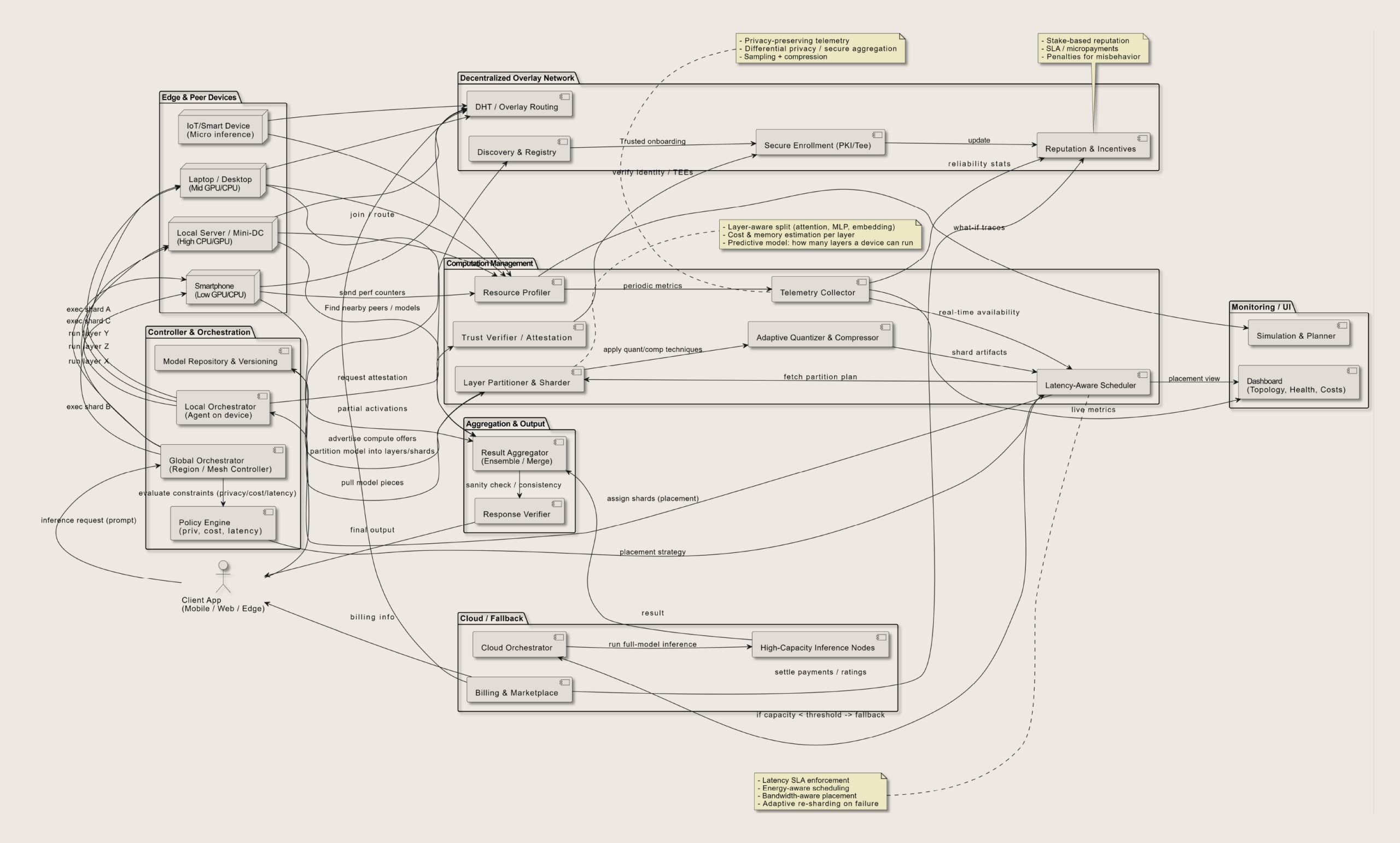
Begin by identifying a node that matches your model’s hardware requirements. Decentralized inference relies on consumer-grade GPUs, so verify that the node has sufficient VRAM and compute power for your specific architecture. Check the node’s reputation score and latency history to ensure reliability. Prime Intellect and similar platforms allow you to filter nodes by these metrics, ensuring your model runs without interruption.
Once a node is selected, upload your model weights and inference script. Most decentralized inference markets require you to package your model into a standardized container format, such as Docker or OCI. This ensures compatibility across different node hardware. Register the model on the network so that the node can pull and execute it. This step often involves setting resource limits to prevent the node from overcommitting its GPU memory.

With the model live on the node, configure the API endpoint to handle incoming requests. You will need to set up authentication keys and define the input/output schema. Most decentralized inference markets provide a unified API gateway that routes traffic to your specific node. Test the endpoint locally to ensure it responds correctly to sample prompts. This configuration is critical for maintaining low latency, which is a primary advantage of decentralized inference.
The final step is to verify that the inference results are correct and that the node is performing as expected. Send a series of test queries through the API and compare the outputs against your local baseline. Monitor the node’s performance metrics, such as token generation speed and error rates. If the node fails to meet your quality standards, you can reassign the workload to another node in the decentralized inference market. This verification loop ensures your AI service remains robust and trustworthy.
Avoid common latency and trust pitfalls
Decentralized inference markets promise lower costs and open access, but they introduce two distinct technical hurdles that can break real-time applications: high latency and unverified outputs. If you are building an agent that needs to respond in under 200 milliseconds, or a financial model that requires audit trails, you cannot treat a decentralized node like a standard cloud API.
Taming Latency
The biggest friction point is network round-trip time. Unlike a centralized data center where GPUs are co-located on the same rack, decentralized inference shards your request across potentially thousands of miles of internet infrastructure. You might find a node with a cheap price, but if it adds 2 seconds to your generation time, the user experience fails.
To mitigate this, you must prioritize proximity and node health over raw price. Always check node latency benchmarks before committing to a provider for real-time apps. Look for nodes geographically close to your end-users or your orchestrator layer. Some marketplaces offer "low-latency" tiers where nodes must meet specific response time SLAs, even if the compute cost is slightly higher.
Ensuring Verifiable Execution
Trust in decentralized inference isn't about hoping the node runs the code correctly; it's about cryptographic proof. In high-stakes environments like algorithmic trading or risk assessment, a manipulated model output could trigger market crashes or financial loss. Verifiable inference becomes mandatory here to ensure the result matches the input.
The solution is to use markets that support Verifiable Computing, such as Zero-Knowledge (ZK) proofs or Trusted Execution Environments (TEEs). These technologies allow the network to prove that the computation was performed correctly without revealing the underlying model weights or data. When selecting a decentralized inference provider, verify if they offer this level of cryptographic assurance. Without it, you are relying on the honesty of a random node, which is a significant risk for production workloads.
Verify inference with on-chain proofs
You need proof that the decentralized node actually ran the model correctly. Without cryptographic verification, there is no way to know if a node tampered with the output or submitted a random guess to collect the reward. In decentralized inference markets, trust is replaced by math.
The standard approach uses zero-knowledge proofs or verifiable computation. The node generates a cryptographic receipt alongside the AI output. This receipt proves the computation was performed on the correct weights and data without revealing the private model or the input prompt. If the proof doesn't match the blockchain record, the reward is automatically rejected.
This mechanism is mandatory for high-stakes applications. As noted in recent research, a manipulated trading model could trigger market crashes. Verifiable inference ensures that algorithmic trading, risk assessment, and fraud detection rely on honest computation rather than opaque black boxes. You are essentially auditing the AI's work in real-time.
Verify your decentralized inference setup
Before launching your workload, run through this pre-deployment checklist to ensure your decentralized inference markets integration is secure and performant. This final verification step bridges the gap between theoretical design and reliable production.
- Network Connectivity: Confirm your nodes can sustain the low-latency connections required for real-time inference, avoiding the bottlenecks common in distributed setups.
- Security Protocols: Verify that data privacy measures are active, ensuring AI processes data locally or within trusted boundaries rather than sending it to distant servers.
- Cost Monitoring: Set up alerts for token price fluctuations or compute usage spikes to prevent unexpected expenses in volatile decentralized economies.
- Verification Layer: Ensure your setup includes mechanisms for verifiable inference, which is mandatory for high-stakes applications like risk assessment or algorithmic trading.
Completing these checks minimizes downtime and ensures your infrastructure can handle the demands of the growing AI inference server market.
Frequently asked questions about decentralized inference
How does decentralized inference differ from centralized models?
Centralized inference sends your data to distant servers to get an answer. Decentralized inference flips this model: the AI comes to your data. This approach keeps sensitive information on local devices or private networks, reducing latency and privacy risks while still leveraging global compute resources.
What is an example of a decentralized market?
The foreign exchange (forex) market is a classic example of a decentralized market because there is no single physical location where traders buy and sell currencies. Similarly, decentralized inference markets operate without a central hub, connecting AI providers and buyers directly through a network.
Can decentralized inference handle real-time tasks?
Latency remains the primary hurdle for real-time applications. While decentralized training is common, inference requires low-latency responses. Current infrastructure works best for tasks that don't demand instant feedback, such as batch processing or non-interactive model serving, rather than live video analysis or high-frequency trading.
No comments yet. Be the first to share your thoughts!