Choose the right verification method
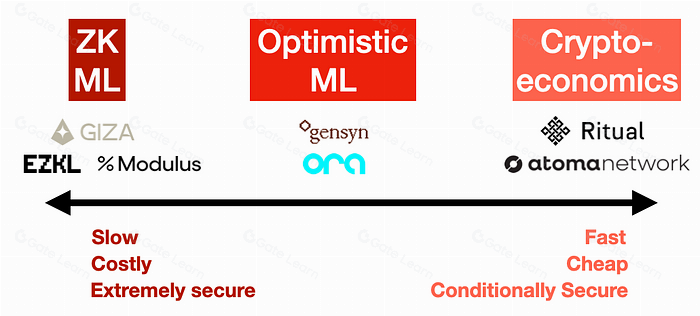
Decentralized inference introduces a specific threat model: computing nodes may behave deceitfully, compromising the integrity of the output. To mitigate this, you must select a trust mechanism that aligns with your application's latency and cost constraints. The three core approaches—zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics—offer distinct trade-offs between security guarantees and computational overhead.
| Method | Cost | Latency | Security |
|---|---|---|---|
| Zero-Knowledge (ZK) | High | High | Highest |
| Optimistic | Medium | Medium | Conditional |
| Cryptoeconomic | Low | Low | Probabilistic |
Zero-knowledge proofs provide the strongest security guarantees by mathematically proving that an inference was executed correctly without revealing the underlying data. However, generating these proofs is computationally expensive and introduces significant latency, making them suitable only for high-value, low-frequency tasks. Optimistic approaches assume validity unless challenged, offering a middle ground where costs are lower but security depends on the presence of active challengers and a dispute resolution period. Cryptoeconomic models rely on financial incentives and slashing conditions to deter malicious behavior, providing the lowest latency and cost but only probabilistic security, which may be insufficient for critical applications.
When building your pipeline, start by defining your acceptable risk tolerance. If you are processing sensitive financial or medical data, the high cost of ZK proofs may be justified by the need for absolute verification. For real-time applications like autonomous driving or high-frequency trading, the latency of ZK proofs is prohibitive, and you may need to rely on cryptoeconomic security with robust monitoring. Optimistic verification serves well in scenarios where occasional delays for dispute resolution are acceptable, balancing cost and security effectively.
Configure the distributed node stack
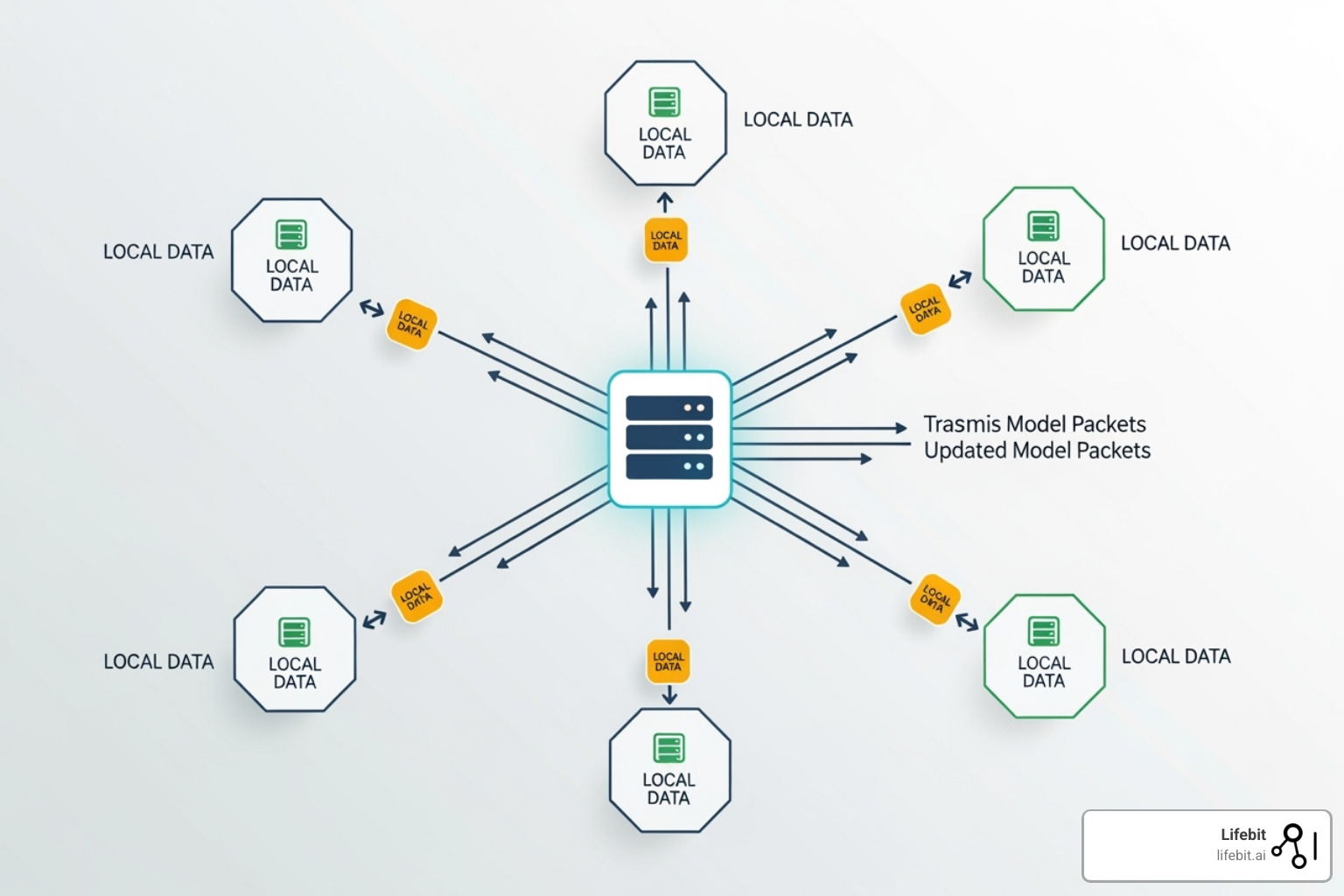
Building a decentralized inference pipeline requires turning independent consumer GPUs into a single, coherent compute resource. The goal is to partition large language models across these nodes and bind them into a network that maintains low latency while distributing the load. This configuration process involves splitting the model weights, establishing communication protocols, and verifying that each node can handle its assigned segment.
Start by dividing the target model into manageable shards. Instead of loading the entire model into a single GPU, use tools like vLLM or DeepSpeed to split the transformer layers across your available hardware. Ensure each shard fits comfortably within the VRAM of its assigned node, leaving a small buffer for activation memory. This partitioning is the foundation of the decentralized inference network, allowing you to scale horizontally by adding more consumer-grade GPUs.
Next, configure the networking layer so nodes can find each other and exchange tensor data. Use a lightweight service discovery mechanism, such as a local DNS or a simple peer-to-peer protocol, to register each GPU node. Implement a high-throughput communication protocol like gRPC or TCP sockets for inter-node communication. This step ensures that when one node finishes processing a layer, it can immediately pass the output to the next node in the chain with minimal delay.
Set up a central router or use a distributed hashing algorithm to direct incoming inference requests to the appropriate node shards. The router should monitor the health and load of each node, rerouting traffic if a GPU becomes overloaded or goes offline. This layer abstracts the complexity of the distributed system from the end user, making the decentralized inference pipeline appear as a single, reliable API endpoint.
Run benchmark tests to ensure the distributed setup meets your performance targets. Measure the end-to-end latency for a standard prompt and compare it against a single-node baseline. If latency is too high, check for network bottlenecks or adjust the model partitioning strategy. Fine-tune the batch size and parallelism settings to optimize throughput without sacrificing response time.
Optimize for low-latency inference
Network latency is the primary bottleneck in decentralized inference. Unlike training, which can tolerate asynchronous updates, inference requires real-time responses to maintain user experience. You must treat geolocation and batching as your first optimization steps, not afterthoughts.
Place workers close to the user
Geographic proximity matters more than raw compute power for latency-sensitive tasks. If your model is hosted on a node in Europe but the user is in Asia, the round-trip time will likely exceed acceptable thresholds for interactive applications.
Use a routing layer that directs requests to the nearest available worker node. This reduces the physical distance data must travel, cutting down on propagation delay. For public-facing services, aim for end-to-end latencies under 100ms, a benchmark that distributed inference stacks are increasingly engineered to meet.
Batch requests strategically
Single requests are expensive and slow due to overhead. Grouping multiple inference requests into a single batch allows the GPU to process them in parallel, improving throughput and amortizing the latency cost.
However, batching introduces a trade-off between security verification and speed. As noted in community discussions, decentralized networks must balance the need for rapid inference with the overhead of verifying worker integrity. Too much batching can increase wait times for individual users, while too little can overwhelm the network with small, inefficient tasks. Find the sweet spot that keeps latency low without sacrificing reliability.
Test reliability and handle failures
A decentralized inference pipeline is only as trustworthy as its weakest node. In a distributed environment, nodes can drop offline, return corrupted outputs, or behave deceitfully to game incentives. You must build systems that detect these failures automatically and reroute work without manual intervention.
Monitor node health continuously
Start by implementing real-time health checks for every participating node. Track latency, uptime, and response accuracy against a known ground truth. If a node’s latency spikes or its outputs deviate from expected patterns, flag it immediately. This visibility allows you to isolate unreliable nodes before they corrupt the entire inference result.
Manage dropped nodes and incorrect results
When a node drops or returns an invalid result, the system must not wait for a timeout. Implement a redundancy layer where multiple nodes compute the same task. Use a consensus mechanism to validate outputs; if two nodes agree and one disagrees, discard the outlier. For critical tasks, require a majority vote before accepting the final inference. This approach mitigates the risk of single-point failures or malicious actors, ensuring the integrity of the decentralized network.
Frequently asked questions about decentralized inference
How does decentralized inference handle latency? Consumer GPU networks can target the 100ms latencies required for public applications, but achieving this requires careful orchestration across distributed nodes. Unlike centralized data centers where blades share low-latency interconnects, decentralized setups must manage network hops between independent machines, making latency management the primary engineering hurdle.
Is decentralized inference secure against malicious nodes? Yes, but it relies on verification rather than trust. The main approaches include zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomic incentives. These mechanisms ensure that even if a computing node behaves deceitfully, the integrity of the inference result remains intact and verifiable.
How does cost compare to centralized cloud providers? Decentralized inference often offers lower costs by leveraging underutilized consumer GPU resources. However, the total cost of ownership includes the overhead of verification and data transmission. While raw compute might be cheaper, the complexity of managing a distributed stack can offset savings for smaller workloads.
No comments yet. Be the first to share your thoughts!