The compute bottleneck driving decentralization
Centralized cloud providers are facing a structural ceiling in AI inference. The global market for inference services has crossed the $100 billion mark, with projections reaching $106 billion by 2025. This scale has created a severe supply-demand imbalance. As agentic AI workloads expand, Goldman Sachs estimates a 24x increase in token generation, pushing GPU availability to its limits.
The result is a volatile pricing environment. Spot prices for high-end accelerators spike during peak demand, making predictable operational costs nearly impossible for mid-sized developers. This scarcity is not a temporary glitch but a fundamental constraint of centralized data center capacity.
Decentralized inference markets are emerging as the necessary counterweight. By aggregating idle GPU capacity from distributed nodes, these networks bypass the bottleneck of monolithic cloud providers. Early research suggests a conservative 5-10% market shift toward decentralized alternatives within the next three years, representing a $10-15 billion opportunity. This shift is driven by the need for cost stability and supply redundancy.
The following chart illustrates the broader compute cost trends that are accelerating this migration.
How decentralized inference markets operate
Decentralized inference markets function as token-coordinated networks that aggregate fragmented GPU resources to serve AI inference requests. Unlike centralized cloud providers that rely on proprietary infrastructure, these networks operate as open marketplaces where supply and demand are matched via smart contracts. Projects such as io.net, Akash, Render, Aethir, and Nosana have established the foundational infrastructure for this shift, creating a liquid market for compute power [src-serp-3].
The technical mechanism relies on a dual-layer architecture designed to balance cost efficiency with low latency. The first layer handles node discovery and resource verification, ensuring that available GPUs meet the specific computational requirements of a given model. The second layer manages the execution of inference tasks, routing requests to the most suitable nodes based on real-time availability and price. This structure allows for scalable deployment without the bottlenecks inherent in traditional data centers [src-serp-6].
Smart contracts serve as the neutral arbiters in this ecosystem. They automatically enforce service level agreements, releasing payments only when inference tasks are completed successfully and verified. This removes the need for trusted intermediaries and reduces the friction associated with billing and contract management. The result is a more resilient compute economy where resources are utilized more efficiently across a global network of providers.
Centralized vs. Decentralized Inference
The structural shift from centralized clouds to decentralized networks is best understood by comparing their operational models. Centralized providers like AWS and Azure offer high control but at a premium cost and with limited flexibility. Decentralized networks prioritize cost efficiency and scalability, leveraging underutilized hardware to drive down prices.
| Feature | Centralized Cloud | Decentralized Network |
|---|---|---|
| Cost Structure | Premium pricing for dedicated instances | Market-driven, often lower costs |
| Latency | Optimized for specific regions | Variable; depends on node proximity |
| Control | Full vendor lock-in and control | Open access, token-coordinated |
| Scalability | Limited by capital expenditure | Elastic, based on global supply |
This comparison highlights the trade-offs. While centralized clouds offer predictable performance, decentralized markets offer economic efficiency and resilience. As the demand for AI inference grows, the ability to tap into a global pool of compute resources becomes increasingly critical for cost management and operational flexibility.
Key protocols shaping the 2026 landscape
The decentralized inference market has moved beyond experimental phases into structured, token-coordinated infrastructure. Leading protocols now compete on three distinct axes: hardware specialization, network scale, and orchestration efficiency. Each project addresses specific bottlenecks in the AI compute supply chain.
io.net: Unified GPU Aggregation
io.net operates as a unified layer that aggregates underutilized GPUs from data centers, crypto miners, and individual users. By abstracting the heterogeneity of hardware, io.net allows developers to submit inference jobs without managing individual node contracts. This aggregation model significantly reduces latency for large language model (LLM) requests. The protocol’s value proposition lies in its ability to offer a single API endpoint for a distributed, global pool of compute resources.
Akash Network: Open-Source Market Place
Akash Network functions as a decentralized cloud marketplace, leveraging Kubernetes for container orchestration. Its open-source nature ensures transparency in pricing and resource allocation. Akash’s primary advantage is cost efficiency; by matching unused compute supply with demand, it often undercuts centralized cloud providers by 50-80%. For inference workloads that require high availability and fault tolerance, Akash’s decentralized architecture prevents single points of failure common in traditional cloud setups.
Render Network: Specialized Graphics and Compute
Originally focused on decentralized GPU rendering for 3D graphics, Render Network has expanded into AI inference. Its specialized node infrastructure is optimized for parallel processing tasks. Render’s integration with Solana provides fast settlement times, which is critical for real-time inference applications. The network’s growth in the AI sector demonstrates how existing decentralized compute infrastructures can pivot to serve the high-bandwidth demands of modern AI models.

Navigating Latency and Reliability Risks
Decentralized inference markets promise lower costs, but they introduce structural latency that centralized GPUs avoid. The network must route requests through distributed nodes, adding hops that traditional data centers do not require. For real-time applications, this overhead can be prohibitive. The trade-off is clear: you gain cost efficiency but sacrifice the sub-millisecond consistency of centralized providers.
Proving computation integrity is the other major hurdle. In a centralized environment, the provider guarantees the code executed correctly. In a decentralized market, the system must verify that the node returned the correct result without re-running the entire inference. This verification process, often involving zero-knowledge proofs or replication, adds computational overhead. It ensures trust but further impacts latency.
Reliability depends on the redundancy of the node pool. If a significant portion of the network goes offline, request failure rates rise. Marketplaces mitigate this by requiring multiple confirmations for a single result. This redundancy increases latency but improves accuracy. The architecture must balance these competing demands to be viable for high-stakes AI applications.
Adopting Decentralized Inference Markets
Enterprise teams must treat decentralized inference as a structural infrastructure shift, not a simple vendor swap. The transition requires rigorous verification of node reliability, latency guarantees, and data sovereignty before production integration.
Verify that the network distributes compute nodes across multiple geographic regions. High-stakes applications require sub-100ms latency, which depends on edge proximity. Test actual response times under load, not just theoretical benchmarks, to ensure consistent performance during peak demand.
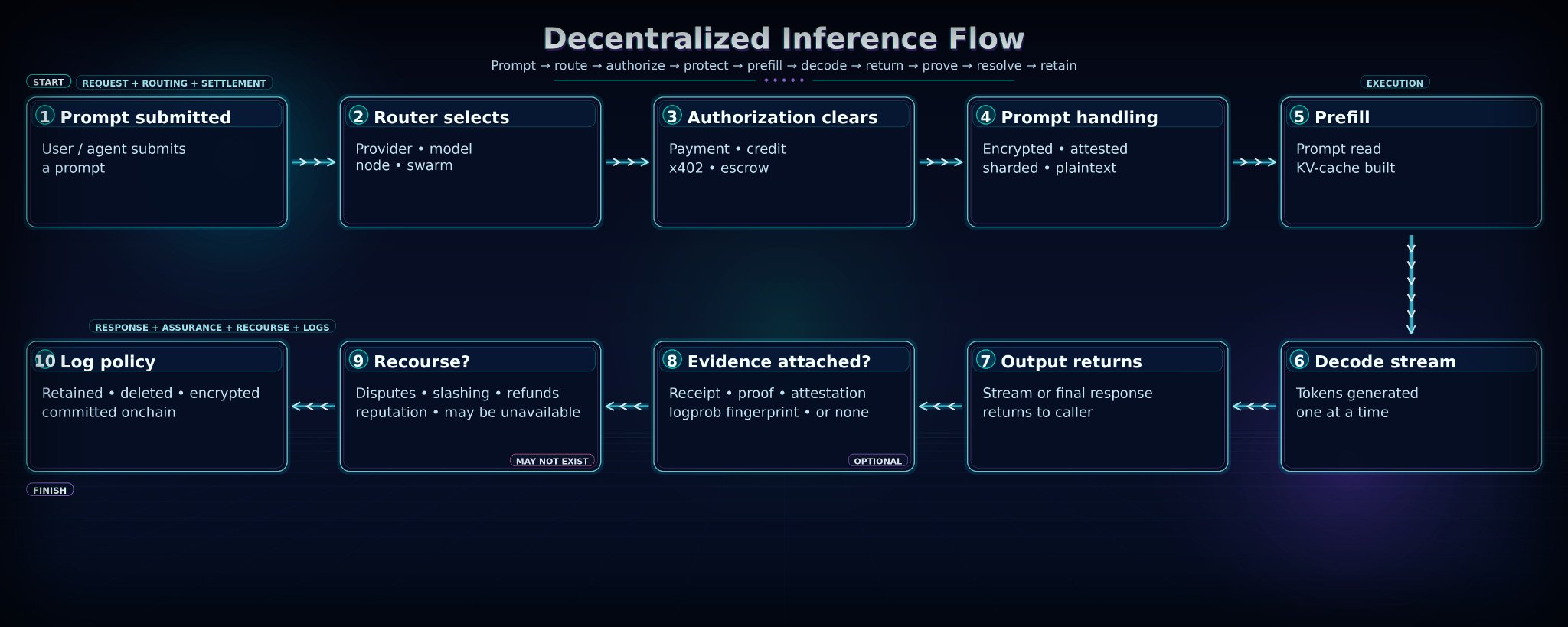
Decentralized networks lack traditional service level agreements. Review the smart contract logic to understand penalty mechanisms for downtime. Ensure the protocol compensates users for failed inferences or delayed responses, creating a financial incentive for node operators to maintain uptime.
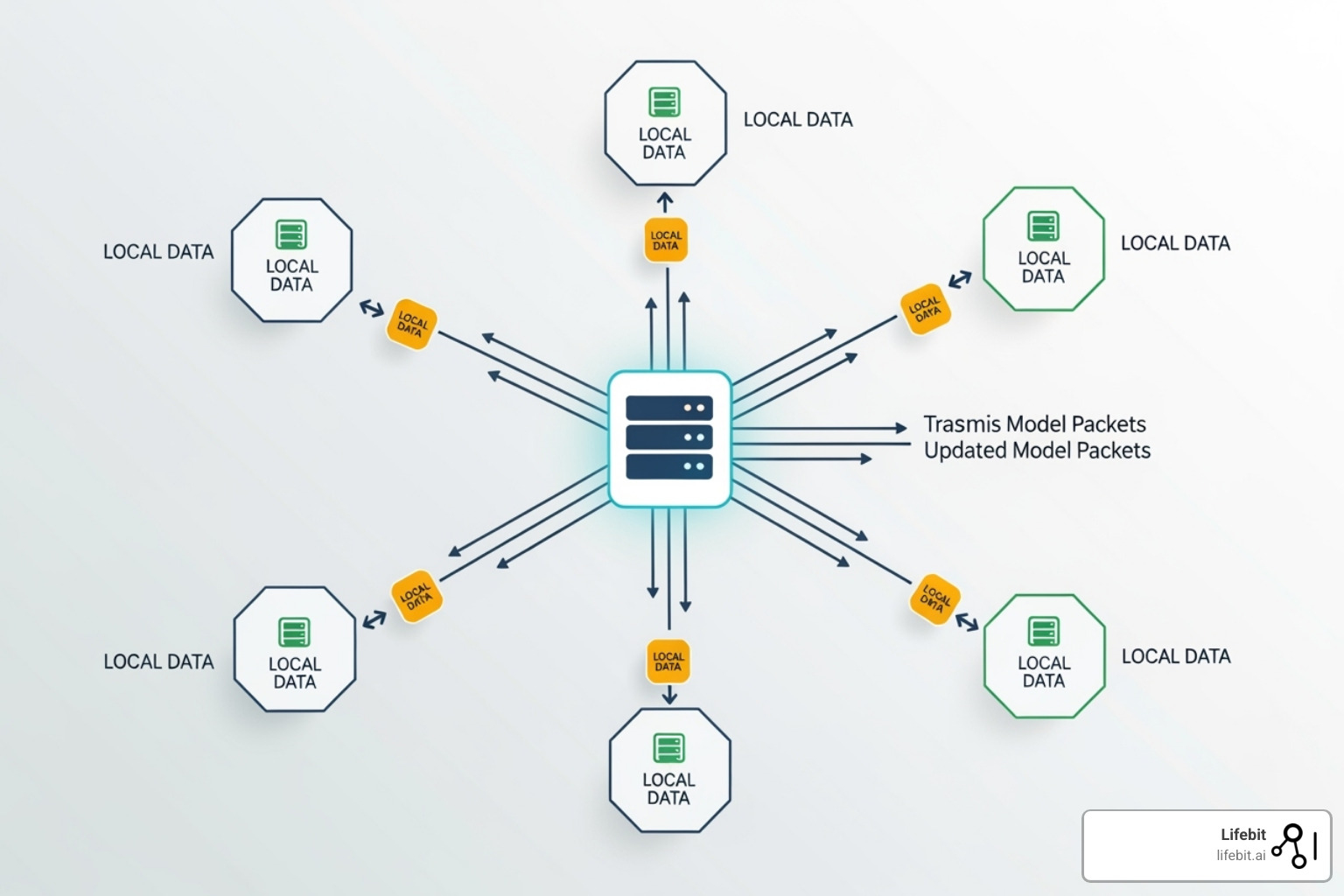
Confirm that inference data is processed in memory without persistent storage on node machines. Look for zero-knowledge proof implementations or trusted execution environments (TEEs) that guarantee data confidentiality. This step is non-negotiable for healthcare, finance, and legal sectors handling sensitive PII.
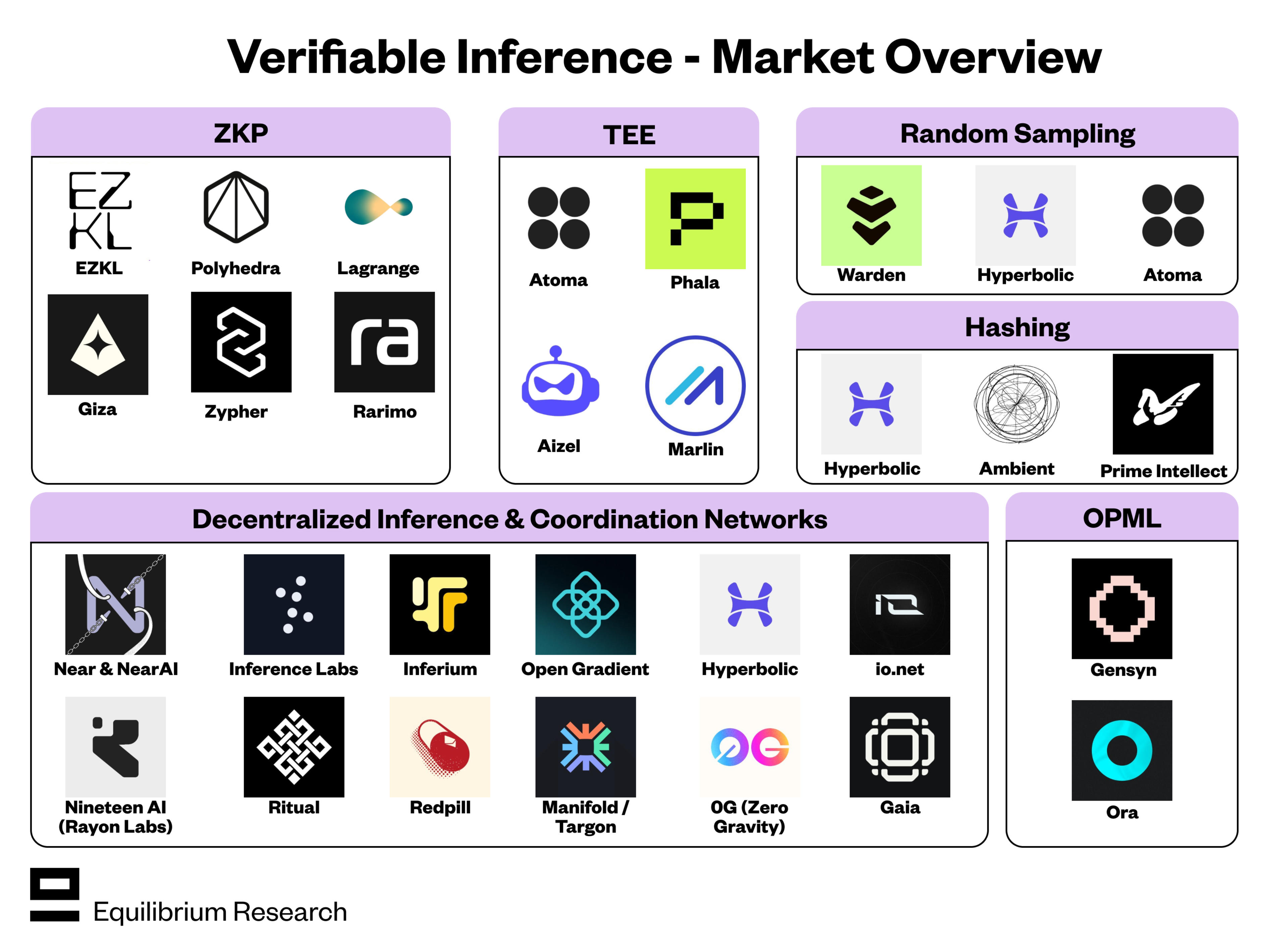
Deploy a small-scale pilot alongside your existing centralized infrastructure. Compare cost efficiency, latency, and accuracy metrics between the decentralized provider and your current vendor. This controlled test reveals integration friction points and validates the economic model before full-scale migration.
No comments yet. Be the first to share your thoughts!