Choose the right inference network
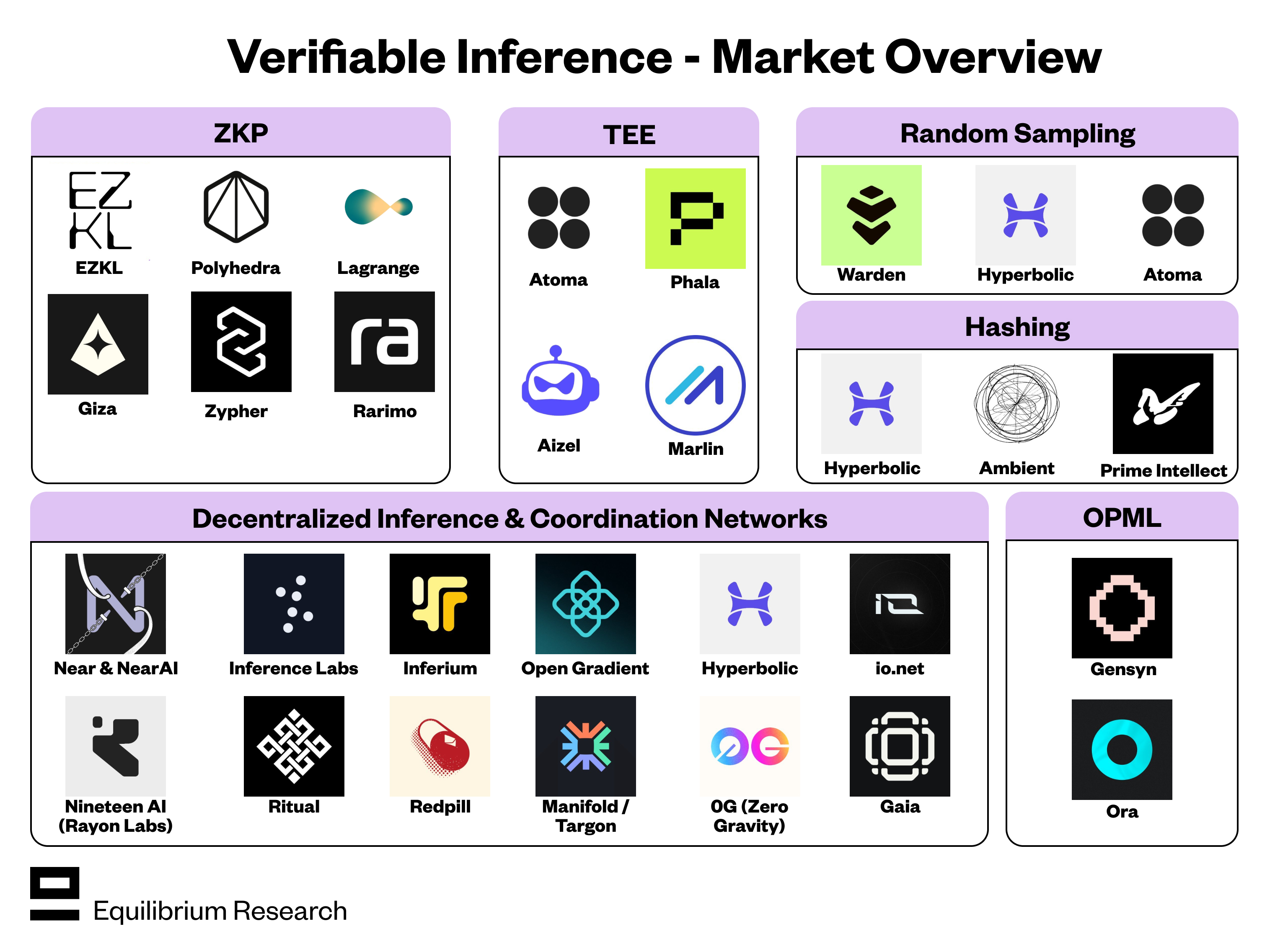
Selecting a decentralized inference provider depends on your agent's specific latency, privacy, and cost constraints. The market has fragmented into distinct infrastructure layers: centralized GPU marketplaces, edge computing networks, and federated learning pools. Each serves a different operational need, and matching the wrong layer to your workload will result in wasted capital or unacceptable performance.
The AI inference market is projected to exceed $250 billion by 2030, with competition driving down costs for standard tasks while premium, low-latency slots remain scarce. Your choice should not be based on price alone, but on the technical architecture required to run your specific model. Below is a comparison of the primary decentralized inference options available in 2026.

| Provider Type | Latency | Cost Profile | Privacy Model | Best Use Case |
|---|---|---|---|---|
| GPU Marketplace | Low | Low | Low | High-volume batch processing |
| Edge Network | Very Low | High | High | Real-time IoT agents |
| Federated Pool | Medium | Medium | Very High | Sensitive healthcare/legal data |
| Agentic Mesh | Variable | Low | Medium | Multi-step autonomous tasks |
GPU marketplaces offer the most cost-effective route for models that do not require real-time responses. Providers rent out idle compute power, allowing you to run large language models at a fraction of the price of cloud giants. However, this comes with lower privacy guarantees, as data is processed on shared hardware without advanced encryption layers.
Edge networks place compute power closer to the data source, drastically reducing latency. This is essential for agents that must react instantly, such as autonomous robotics or live trading bots. The trade-off is higher cost and limited model availability, as edge devices often lack the memory to run massive parameter models.
Federated learning pools are designed for data sensitivity. Instead of sending raw data to a central server, the model travels to the data. This is the only viable option for handling protected information like medical records or legal documents, though it typically introduces higher latency due to the complex coordination required.
Agentic mesh networks are an emerging category where multiple agents collaborate to distribute inference tasks. This approach is ideal for complex, multi-step workflows where no single node can handle the entire load. While flexible, the variable latency makes it unsuitable for time-critical applications.
Configure the agent wallet for payments
To execute requests on decentralized inference markets, your AI agent needs a dedicated wallet capable of handling micro-transactions and gas fees. This wallet acts as the agent's identity and payment rail, allowing it to pay GPU providers without manual intervention.
1. Create a dedicated agent wallet
Do not use your primary holding wallet. Instead, generate a new, isolated wallet specifically for agent activities. This limits exposure if the agent's smart contract interactions are compromised. Most AI agent frameworks (such as LangChain or AutoGen) support integration with wallets like MetaMask, Phantom, or built-in web3 providers.
2. Fund the wallet with stablecoins and native gas tokens
Decentralized inference markets typically require two types of funds:
- Stablecoins (USDC/DAI): Used to pay for the actual compute resources. Using stablecoins avoids volatility during the inference process.
- Native Gas Tokens (ETH, SOL, etc.): Required to pay for transaction fees on the blockchain. Ensure the wallet has enough gas to sign requests and verify results.
3. Set up spending limits and allowances
Configure the wallet to interact only with verified marketplace contracts. Set strict daily spending limits to prevent runaway costs if the agent enters an infinite loop or encounters a malicious provider. Use smart contract allowances rather than approving unlimited token access.
4. Test with a small request
Before scaling, send a low-cost inference request to verify that the wallet can sign transactions, pay gas, and receive results. Monitor the transaction hash on the blockchain explorer to confirm the payment flow works as expected.
Verify proofs of inference
When you submit a task to a decentralized inference market, you are trusting a network of anonymous nodes to run your model correctly. You cannot simply take their word for it. The system uses cryptographic proofs to guarantee that the output matches the input, the model weights, and the execution environment. Without this verification, the entire decentralized value proposition collapses into a trustless gamble.
1. Understand the Verifiable Computing Layer
The core of verification is verifiable computing. This technology allows a node to generate a cryptographic receipt (a proof) that it executed a specific computation correctly. The most common methods today are Zero-Knowledge (ZK) proofs and Verifiable Delay Functions (VDFs).
- ZK-Proofs (zkVM): These generate a proof that the program executed correctly without revealing the underlying data. They are computationally expensive to generate but cheap to verify.
- VDFs: These ensure that a certain amount of time has passed, preventing nodes from rushing or cheating the timing requirements of the inference task.
Why proof-of-inference is critical for high-stakes AI decisions in finance and healthcare.
2. Check the Model Integrity
Before the node even starts computing, the system must ensure it is running the exact model you requested. Decentralized inference markets typically use Merkle Trees to hash the model weights.
- The model creator publishes the root hash of the model weights to the blockchain.
- The node retrieves the weights and computes its own hash.
- If the hashes do not match, the proof is rejected immediately.
This prevents nodes from swapping in a cheaper, less accurate model to save on compute costs. You get exactly what you paid for.
3. Verify the Execution Proof
Once the node finishes the inference, it submits the output along with the cryptographic proof. The verification layer (often a smart contract or a specialized verifier node) checks the proof.
- Input Check: Did the node receive the correct prompt or data?
- Computation Check: Did the node perform the correct matrix multiplications and activations?
- Output Check: Does the generated proof match the final result?
If the proof validates, the smart contract releases the payment to the node. If it fails, the node is slashed (penalized) and removed from the network. This economic incentive ensures that honest behavior is the only profitable path.
4. Audit the Node Reputation
Verification is automated, but reputation is manual. Most decentralized inference markets track node performance over time. Nodes with a history of failed proofs or slow response times are flagged.
- Slashing Events: Check if the node has been slashed for invalid proofs.
- Uptime: Ensure the node has been consistently online.
- Speed: Compare the node's response time against the network average.
You can filter your job submissions to only include nodes with a high reputation score. This adds a layer of human oversight to the automated cryptographic verification.

Monitor latency and token costs
To ensure your decentralized inference setup remains viable, you must track two metrics simultaneously: token costs and latency. In 2026, the market is defined by simultaneous deflation and expansion, with per-token costs falling 80% or more while total demand expands. This means a static budget quickly becomes obsolete. You need a live view of your spend relative to performance.
Start by setting up a dashboard that pulls real-time data from your chosen inference provider. For many users, this means integrating with platforms like OpenRouter, which aggregates multiple models and provides transparent pricing data. Compare these live rates against your primary centralized cloud provider's standard API pricing. If the decentralized option does not show a clear cost advantage during peak usage, the latency savings may not justify the operational complexity.
Latency is the second half of the equation. A cheaper token is useless if the inference takes five seconds instead of one. Monitor your average response time per request. If latency spikes, check if the node distribution is causing bottlenecks or if the model choice is too heavy for your use case. Adjust your routing logic to favor faster nodes even if they cost slightly more per token, maintaining a balance between speed and budget.
Use a technical chart to visualize the relationship between decentralized AI token prices and centralized cloud compute costs over time. This helps you spot trends, such as when decentralized networks become cheaper during high-demand periods, allowing you to automate spending shifts.
Common integration mistakes to avoid
The easiest mistake with Use Decentralized Inference Markets is changing too much at once. Rename devices, move networks, update firmware, or adjust permissions one at a time. When setup fails, the last change should be obvious enough to undo without rebuilding the whole configuration. Do not treat a successful app screen as the final test. Use the physical control, the app, and any connected automation to confirm the setup works from every path the reader will actually use.
The simplest way to use this section is to keep the setup small, verify each change, and record the stable configuration before adding optional accessories.
FAQ about decentralized inference markets
Work through to Decentralized Inference Markets
No comments yet. Be the first to share your thoughts!