Why enterprises seek decentralized inference
Enterprises are facing a dual squeeze on their AI budgets. First, cloud GPU prices have surged as demand for generative AI outpaces the supply of high-end chips. Second, relying on a single cloud provider creates vendor lock-in and limits the ability to scale during traffic spikes. This combination has made traditional centralized inference models increasingly expensive and fragile.
Decentralized inference offers a way out by distributing compute tasks across a broader network of nodes rather than concentrating them in massive data centers. Instead of leasing expensive instances from a single provider, organizations can tap into idle or underutilized GPU resources from a distributed pool. This approach not only lowers costs but also diversifies the underlying infrastructure, reducing the risk of outages.
The economic pressure is real. As AI workloads grow, the cost of maintaining consistent, low-latency inference services in centralized clouds continues to rise. Distributed networks allow companies to treat compute as a commodity, similar to how energy grids balance supply and demand across different sources. This shift enables more flexible scaling and better cost control, making it an attractive option for enterprises looking to optimize their AI spending without sacrificing performance.
How distributed GPU networks route requests
Traditional cloud inference relies on monolithic servers. A single request hits one machine, demanding it hold the entire model in VRAM. This creates a bottleneck. When demand spikes, that single node saturates, leading to latency spikes or dropped connections. The cost is equally rigid: you pay for the most expensive GPU in the cluster, even if only a small fraction of its capacity is used for a specific task.
Decentralized inference solves this by treating GPU hardware as a fluid pool rather than a static server. Instead of sending a request to one endpoint, the system routes it across a network of heterogeneous nodes. This approach mirrors how the internet itself works: data packets travel different paths to reach a destination, avoiding congestion. In AI inference, the "data" is the computation required to generate a response.
The routing mechanism operates in three distinct phases: partitioning, distribution, and aggregation. Each phase relies on specialized software that understands the topology of the available network and the capabilities of individual GPUs.
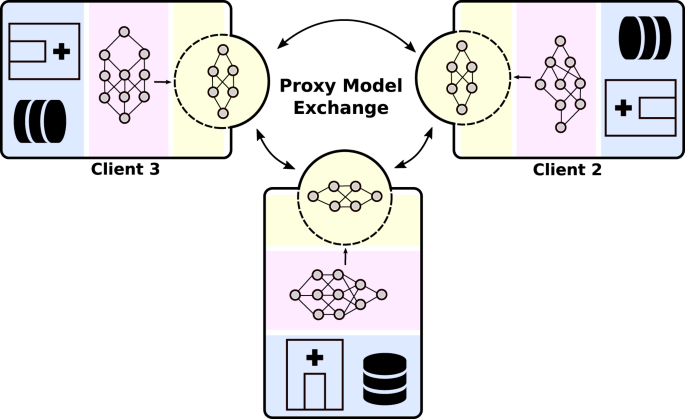
The process begins by slicing the neural network into smaller, independent blocks. Unlike traditional serving where the entire model lives on one GPU, decentralized systems break the model into layers or tensor chunks. This allows different parts of the model to run on different hardware, whether it’s a high-end data center GPU or a consumer-grade card. The partitioning strategy is critical; it must minimize the amount of data passed between nodes to keep latency low.
Once partitioned, the inference engine identifies which nodes can handle specific blocks. It considers factors like current load, memory availability, and network latency between nodes. A request might be split so that the first few layers run on a nearby edge device, while deeper, more complex layers are sent to a powerful remote server. This dynamic routing ensures that no single node becomes a choke point, effectively balancing the load across the entire network.

As each node completes its portion of the computation, the intermediate outputs are passed to the next node in the chain. This continues until the final layer produces the result. The system then aggregates these outputs into a single coherent response. Because the communication happens in parallel across the network, the total time to completion is often significantly faster than waiting for a single overloaded server, while the cost is distributed among many providers.
This architecture fundamentally changes the economics of AI. By utilizing underused GPU capacity from diverse sources, providers can offer inference at a fraction of the cost of major cloud vendors. The trade-off is increased complexity in managing network reliability and ensuring data privacy across untrusted nodes, but for many applications, the cost and scalability benefits outweigh these challenges.
Verifying results without trusting nodes
The promise of decentralized inference is simple: access cheap, abundant GPU power. The reality is a new threat model. In a centralized cloud, the provider guarantees the hardware works as advertised. In a distributed network, you are renting compute from strangers. The risk is that a node returns a random or manipulated output to save time, or worse, that the model itself is compromised.
Without a way to verify the work, the cost savings are meaningless if the output is garbage. This is the core technical hurdle of decentralized inference. To solve it, the ecosystem has converged on three primary verification mechanisms, each trading off speed, cost, and security.
Zero-Knowledge Machine Learning (ZKML)
ZKML is the most mathematically rigorous approach. It allows a node to generate a cryptographic proof that it executed the correct inference without revealing the underlying data or the model weights. Think of it like a sealed envelope: you can verify the seal is intact and the signature is valid without ever opening the letter.
The downside is computational overhead. Generating these proofs is expensive and slow, often requiring the node to perform the calculation multiple times. This makes ZKML currently viable only for smaller models or specific verification tasks, rather than massive large language model (LLM) inference at scale.
Optimistic Fraud Proofs
Optimistic verification operates on the assumption that nodes are honest by default. The network accepts the result immediately, but allows a "challenger" period where other nodes can review the work. If a challenger detects a discrepancy, they submit a fraud proof.
This approach is much faster and cheaper than ZKML because it avoids heavy cryptography for every single inference. However, it introduces a delay. If a malicious node submits a bad result, you must wait for the challenge window to close before you can trust the output or penalize the liar. It’s a trade-off between speed and finality.
Cryptoeconomic Incentives
The third pillar relies on skin in the game. Nodes must stake tokens to participate in the network. If they are caught providing incorrect results—whether through fraud proofs or reputation systems—they lose their stake (slashing). This aligns the economic interests of the node operators with the integrity of the network.
While no cryptographic proof is generated, the financial risk of cheating acts as a powerful deterrent. This method is often combined with optimistic or ZK approaches to create a layered security model. The cost of verification is shifted from computation to economics, making it the most scalable solution for today’s infrastructure.
Latency tradeoffs in public internet inference
The promise of decentralized inference is cost savings, but the public internet introduces a hidden tax: latency. When you route requests through a distributed network of uncoordinated GPUs, data must travel across unpredictable hops. For batch processing, this delay is negligible. For real-time applications like chatbots or live video analysis, even a 100-millisecond increase can break the user experience.
High latency isn't just a speed issue; it compounds costs. If a request times out or requires retries due to slow node responses, you waste compute cycles. This is why many decentralized platforms struggle with real-time workloads. The network must handle packet loss, variable bandwidth, and the physical distance between the user and the nearest available GPU.
To mitigate this, architects use two main patterns: edge caching and model partitioning. Edge caching keeps popular model weights closer to the user, reducing the round-trip time for initial loading. Model partitioning splits the inference task, sending different layers of the neural network to different nodes. This requires sophisticated orchestration but can balance load and reduce bottlenecks.
| Pattern | Best Use Case | Latency Impact | Complexity |
|---|---|---|---|
| Edge Caching | High-frequency, same-model requests | Low | Medium |
| Model Partitioning | Large models, low-bandwidth networks | Medium | High |
| Full Decentralization | Batch processing, non-real-time | High | Low |
The choice depends on your tolerance for delay. If your application can wait, decentralized inference offers a cheap, scalable backbone. If it needs instant answers, you may need to hybridize with centralized edge servers to bridge the gap.
Implementation checklist for enterprises
High costs and GPU supply shortages are forcing engineering teams to look beyond centralized clouds. Before committing to a decentralized inference provider, you must verify that the network can handle your specific latency and security needs. This checklist helps you evaluate whether a provider fits your operational requirements.
-
Verify node uptime guarantees and p99 latency metrics for your target region.
-
Confirm zero-knowledge proof or fraud proof mechanisms for output integrity.
-
Audit data privacy policies to ensure inference data is not stored or reused.
-
Test failover procedures when a node drops during active inference.
-
Calculate total cost including network fees versus centralized cloud pricing.
Common questions about decentralized inference
You might be wondering if decentralized inference is actually secure, how it handles latency, and whether it fits your existing stack. Here are the answers to the most pressing concerns.
How is inference verified without a central authority?
Since there is no single server to trust, the network uses cryptographic methods to prove the AI did the math correctly. The three main approaches are zero-knowledge proofs, optimistic fraud proofs, and cryptoeconomics. This "don't trust, verify" model ensures that even if a node acts maliciously, the result can be challenged and corrected by the network. Read more on verification models.
Does decentralization introduce high latency?
Not necessarily. While splitting requests across nodes adds some overhead, many decentralized networks use a dual-layer architecture to keep speeds competitive. By optimizing how tasks are routed and cached, these systems can deliver low-latency responses suitable for real-time applications, often matching or beating centralized cloud providers.
Is decentralized inference cheaper than AWS or Azure?
It often is. By leveraging idle GPU capacity from a global network of providers, decentralized inference avoids the premium pricing of dedicated cloud instances. This model is particularly cost-efficient for large language model deployments, allowing projects to scale without the massive infrastructure bills associated with traditional AI hosting.
No comments yet. Be the first to share your thoughts!